A practical guide to web data QA part III: Holistic data validation techniques
In case you missed them, here’s the first part and second part of the series.
The manual way or the highway...
In software testing and QA circles, the topic of whether automated or manual testing is superior remains a hotly debated one. For data QA and validation specifically, they are not mutually exclusive. Indeed, for data, manual QA can inform automated QA, and vice versa. In this post, we’ll give some examples.
Web data QA: Pros and cons - manual vs automated tests
It is rare that data extracted from the web can be adequately validated with automated techniques alone; additional manual inspections are often needed. The optimal blend of manual and automated tests depends on factors including:
- The volume of data extracted
- Cost of automated test development
- Available resources
When considered in isolation, each has its benefits and drawbacks:
Automated tests
Pros:
- Greater test coverage (in the case of data, this means whole-dataset validation can be performed)
- Speed
- Hands-free, typically not requiring human intervention (in the case of a dataset as opposed to an application)
- Easier to scale
Cons:
- False alarms
- Development effort; the time is taken to develop once-off, website-specific validation might be better spent on thorough manual QA
Manual tests
Pros:
- Some tests can't be automated; this forces rigorous attention to detail that only a human eye can provide
- Usually better for semantic validation
- The “absence of evidence != evidence of absence” problem; visual inspection of websites can and does uncover entities that the web scraper failed to extract; automation validation struggles with this aspect.
Cons:
- Slow
- Prone to human error and bias
- Time-consuming
- Repetition takes a lot of time and effort
Combining manual and automated validation
Automated testing is most suitable for repetitive tasks and regression testing when rules are clearly defined and relatively static, this includes things like:
- Duplicated records;
- Trailing/leading whitespaces;
- Unwanted data (HTML, CSS, JavaScript, encoded characters);
- Field formats and data types;
- Expected patterns;
- Conditional and inter-field validation; etc.
Manual tests, on the other hand, are invaluable for a deeper understanding of suspected data quality problems, particularly for data extracted from dynamic e-commerce websites and marketplaces.
From a practical point of view, the validation process should start with an understanding of the data and its characteristics. Next, define what rules are needed to validate the data, and automate them. The results of the automation will be warnings and possible false alarms that need to be verified using manual inspection. After the improvement of the rules, the second iteration of automated checks can be executed.
Semi-automated techniques
Let's suppose we have the task of verifying the extraction coverage and correctness for this website: http://quotes.toscrape.com/
The manual way
If you try to achieve this task in a fully manual way, then you usually have the following options:
- Testing several examples per page sequentially or randomly;
- Simply looking over the extracted data with a spreadsheet program or simple text editors relying on their filters or other techniques;
- Copy & paste, sorting, and then comparing - it would require a lot of time.
The automated way
The same task can be easily done with an automation tool. You will need to spend some time investigating what needs to be extracted, do some tests, and voila. However, there are some points to be aware of:
- You might need to know a bit of coding;
- You may need to understand CSS and XPath;
- You could know how to setup Selenium;
- Validation with JSON Schema (covered in part I).
What is a happy middle ground?
To mitigate most of the cons of the manual and automated approaches, we can tackle the task using a semi-automated approach.
Step 1: Study the page, noting that there are 10 results per page and clear pagination: http://quotes.toscrape.com/page/2/
The last page is 10.
Step 2: Open all pages. You can use browser extensions like Open Multiple URLs
If you’d like to build such a list you can use excel: defining a template and simple formula:
=$B$1 & A3 & "/"
Open all links with the above extension.
Step 3: Extracting the data. Now we can extract all quotes per page with a few clicks. For this purpose, we are going to use another browser extension like Scraper.
Upon installing the extension, for example, this is how we can extract all authors:
Select the name of the first author of the page you are in, right-click on it and then click on “Scrape similar…”:
Then you will get the following window opened. Export it elsewhere or simply within the window, use it to compare with the data previously extracted:
Lessons learned
Given a scenario of having failing data quality checks towards product data extracted from the web with only tests for prices, the tools and approaches we have covered so far since the beginning of our series are capable of detecting different errors like:
- Invalid price formats;
- An unusual difference in the prices;
- Promotions (having different applicable prices);
- Not extracting the price at all.
That said, the automated tests can fail to validate and report the wrong price because of a combination of different factors. Just to start, the total dependence on automated validation leads to a false sense of “no errors”, not to mention that if crucial care is not taken such as following the steps we covered in our series so far will lead to lower-than-possible test coverage.
The key lesson here is that even when automation is done in the best way possible, it can still fail us due to nuances on the websites, or miss some edge cases like on less than 1% of the data - that’s why it’s important to maintain and support automated tests with manual validations.
Too many false positives or a false sense of “no errors”
While building a JSON Schema we can try to be so strict on the data validation rules using as much as the validation definitions rules there are to assert the data to the best possible such as the following for price, for example:
{ "type": "object", "properties": { "price": { "type": "number", "minimum": 0.01, "maximum": 20000, "pattern": "^[0-9]\.[0-9]{2}$" }, "productName": { "type": "string", "pattern": "^[\S ]+$" }, "available": { "type": "boolean" }, "url": { "format": "uri", "unique": "yes" } }, "required": [ "price", "productName", "available", "url" ] }
However, every website has a different behaviour, many won’t have the price at all whenever the product is out of stock and it’s expected for our extraction tool to set the price to 0 for such cases so, what’s better? Be more lenient with our tests removing the "minimum" validation? No! There’s another approach that we can take with more knowledge of the JSON Schema validation possibilities and that is conditionals:
{ "type": "object", "properties": { "productName": { "type": "string", "pattern": "^[\S ]+$" }, "available": { "type": "boolean" }, "url": { "format": "uri", "unique": "yes" } }, "if": { "properties": { "available": { "const": false } } }, "then": { "properties": { "price": { "const": 0 } } }, "else": { "properties": { "price": { "type": "number", "minimum": 0.01, "maximum": 20000, "pattern": "^[0-9]\.[0-9]{2}$" } } }, "required": [ "productName", "price", "available", "url" ] }
So with this new second schema, we can prevent both the situations of having too many false-positive errors being raised (Happens when using 1st JSON Schema shown above) and also a misleading absence of errors (if we simply removed the minimum tag for price) which could lead us to miss the extraction of price even when the product was in stock due to malfunctioning or changes on the website.
Edge cases and relying totally on automation
It’s clear that a manual+automated approach is the way to go.
Let’s have an example of receiving the following sample data for the extraction of http://quotes.toscrape.com/page/1/ to assess its quality:
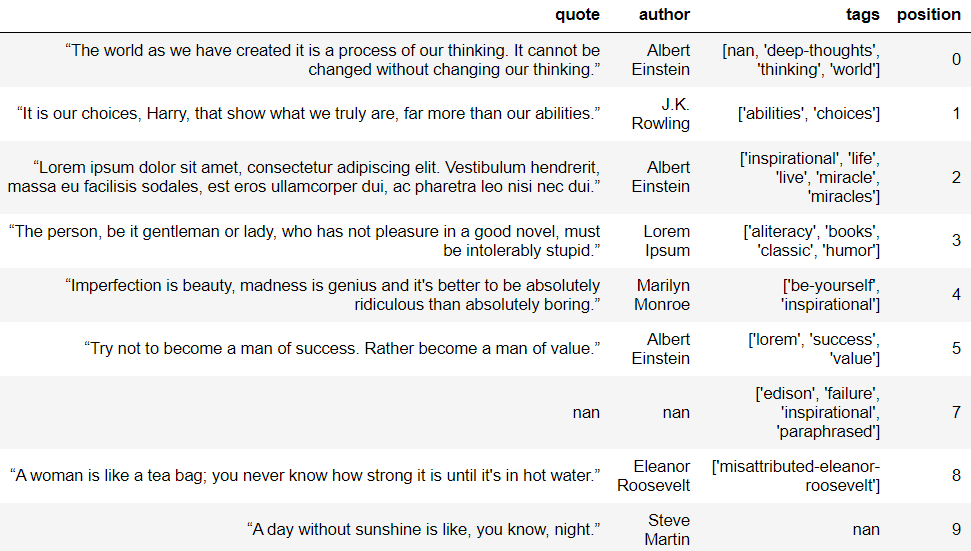
Automated tests are able to catch every single one of the values that failed to be extracted that are highlighted in green below (Null/NaN values), however, the following issues in red won’t be caught without an additional step of manual or semi-automated approach:

So taking on the possibility of using e.g. Selenium and the data on hands, we can build a script to check the coverage and that if the data extracted was indeed the one available for every single one of the cells:
# Preparing the Selenium WebDriver import time from selenium import webdriver from selenium.webdriver.chrome.options import Options
driver = webdriver.Chrome(executable_path=r"chromedriver", options=Options()) driver.get("http://quotes.toscrape.com/page/1/") time.sleep(15)
# Extraction coverage test is_item_coverage_ok = df.shape[0] == len( driver.find_elements_by_xpath("//*[@class='quote']") ) if is_item_coverage_ok: print("Extraction coverage is perfect!") else: print( "The page had " + str(len(driver.find_elements_by_xpath("//*[@class='quote']"))) + " items, however, only " + str(df.shape[0]) + " were extracted." ) # Testing if each column for each row matches the data available on the website # And setting the IS_OK column of them accordingly for row, x in df.iterrows(): is_quote_ok = ( x["quote"] == driver.find_element_by_xpath( "//div[" + str(x["position"] + 1) + "]/span[contains(@class, 'text')]" ).text ) is_author_ok = ( x["author"] == driver.find_elements_by_xpath("//small")[x["position"]].text ) are_tags_ok = True if isinstance(x["tags"], list): for tag in x["tags"]: if isinstance(tag, str): tags = driver.find_elements_by_xpath("//*[@class='tags']")[ x["position"] ].text if tag not in tags: are_tags_ok = False break else: are_tags_ok = False else: are_tags_ok = False df.at[row, "IS_OK"] = is_quote_ok and is_author_ok and are_tags_ok driver.close() df.style.hide_index()
Which returns us the following Pandas DataFrame:
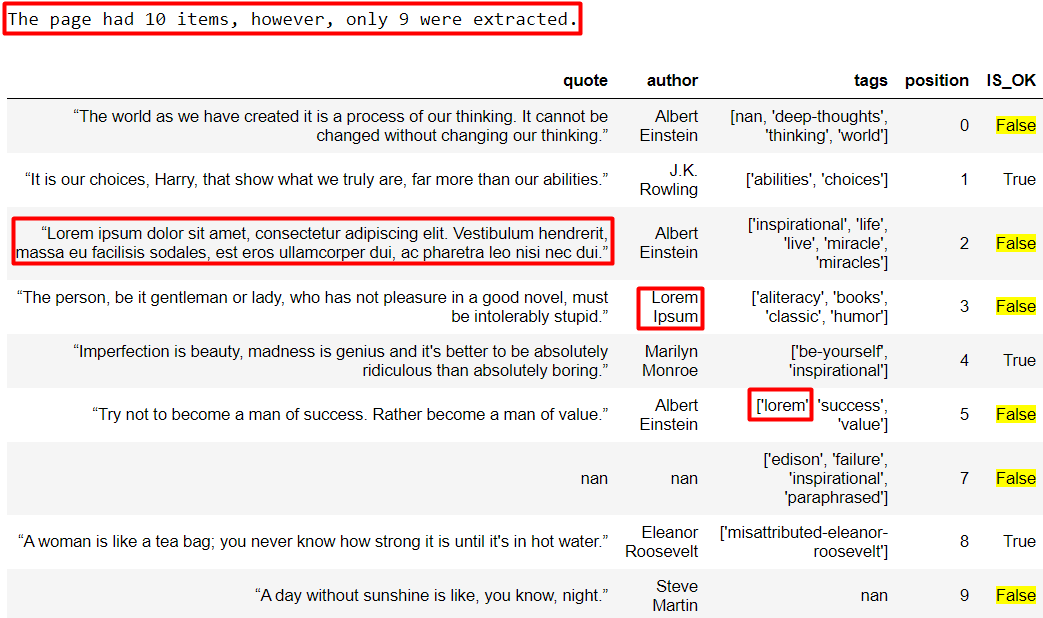
This combined approach allowed us to detect 4 additional issues that would have slipped past standard automated data validation. The full Jupyter notebook can be downloaded here.

Conclusions
In this post, we showed how automated and manual techniques can be combined to compensate for the drawbacks of each and provide a more holistic data validation methodology.
In the next post of our series, we’ll discuss some additional data validation techniques that straddle the line between automated and manual.
Check out part 4 and part 5 of the series.
Do you need a High Quality web data extraction solution?
At Zyte , we extract billions of records from the web everyday. Our clients use our web data extraction services for price intelligence, lead generation, building a product and market research, among other things.
If you and your business’s success depends on web data, reach out to us and let’s discover how we can help you with web data!