New changes to our Scrapy cloud platform
We are proud to announce some exciting changes we've introduced this week. These changes bring a much more pleasant user experience, and several new features including the addition of Portia to our platform!
Note: Portia is no longer available for new users. It has been disabled for all the new organisations from August 20, 2018 onwards.
Here are the highlights:
An Improved Look and Feel
We have introduced a number of improvements in the way our dashboard looks and feels. This includes a new layout based on Bootstrap 3, a more user-friendly color scheme, the ability to schedule jobs once per month, and a greatly improved spiders page with pagination and search.
Filtering and pagination of spiders:
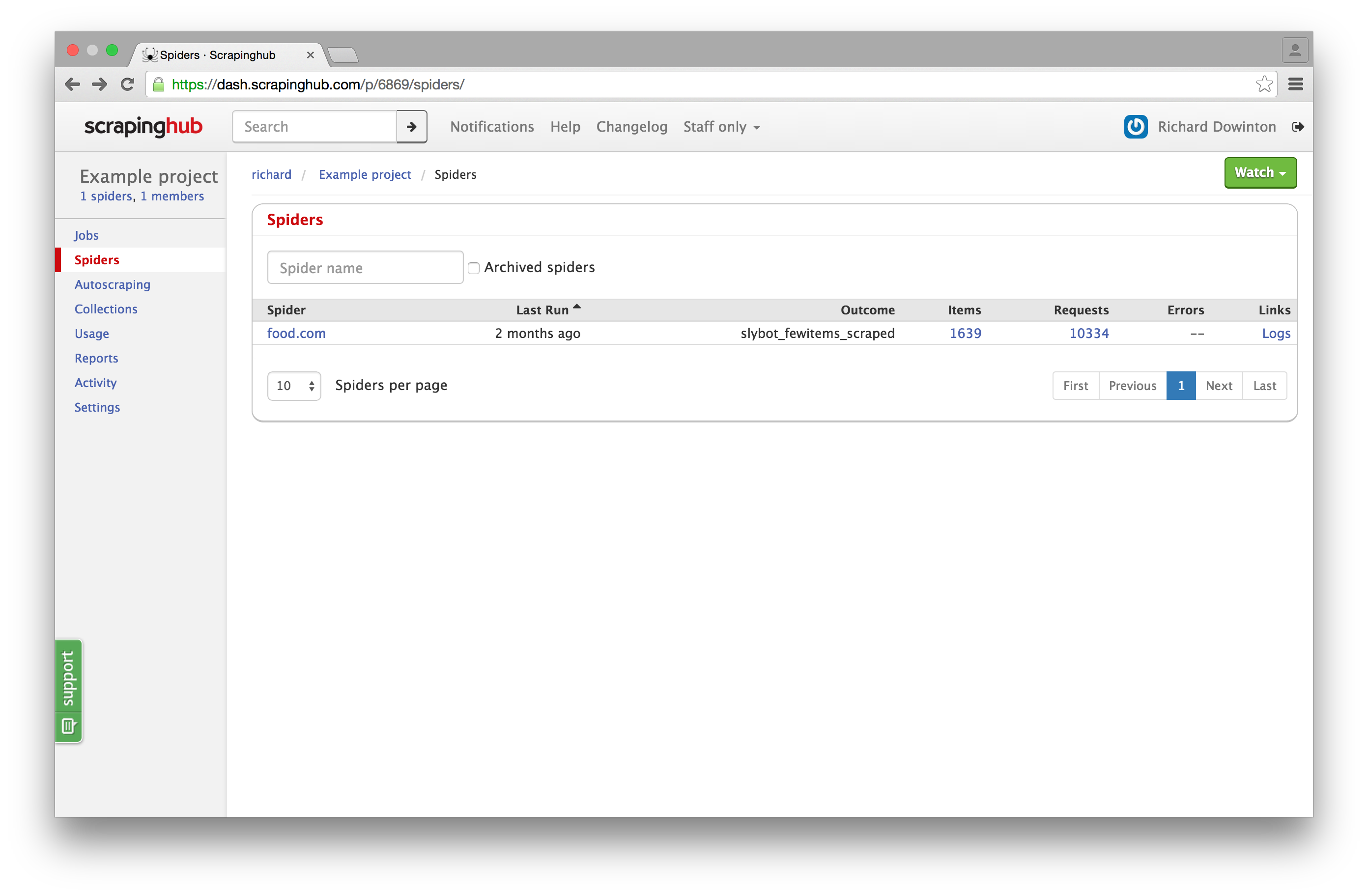
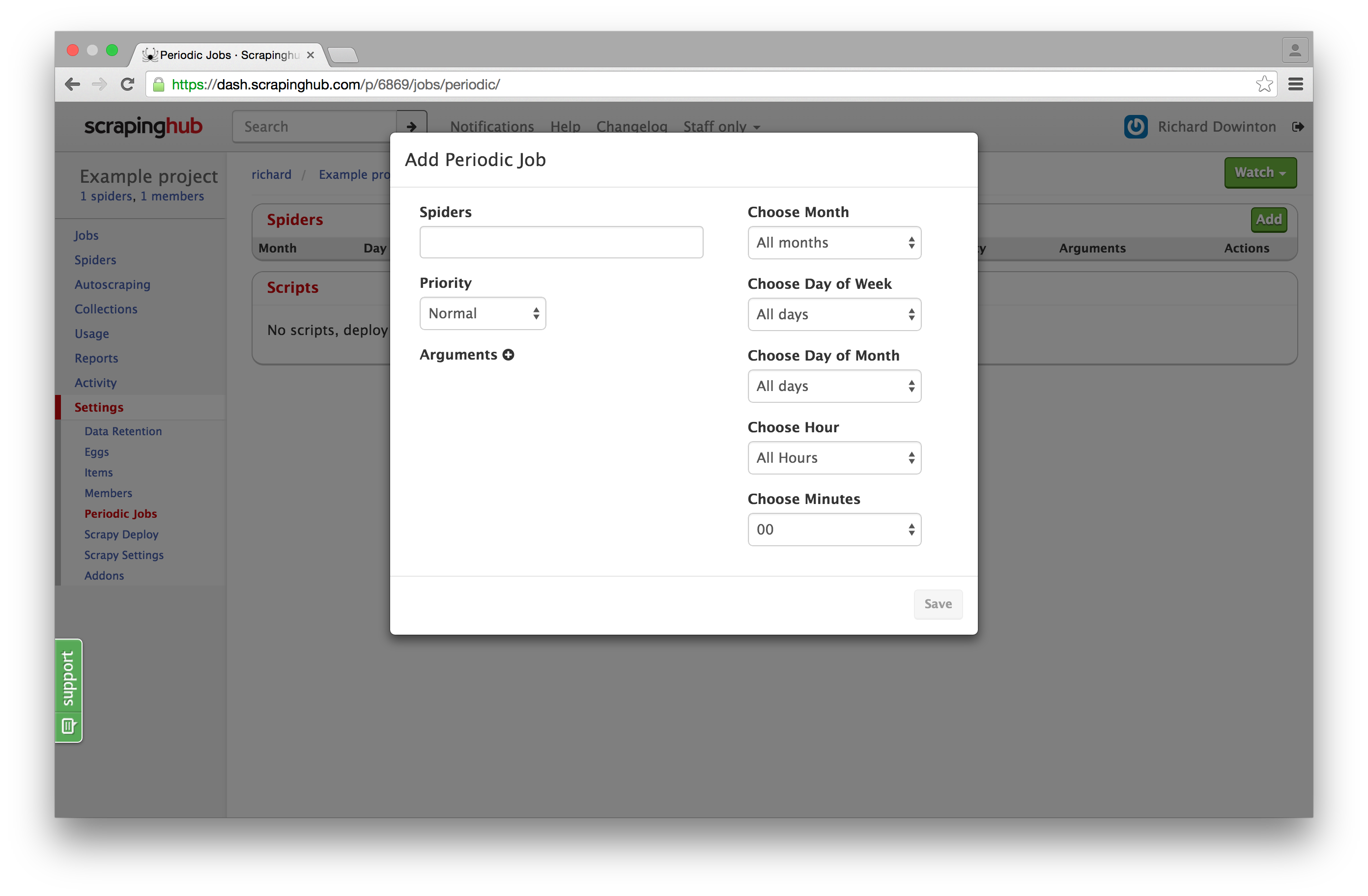
A new user interface for adding periodic jobs:
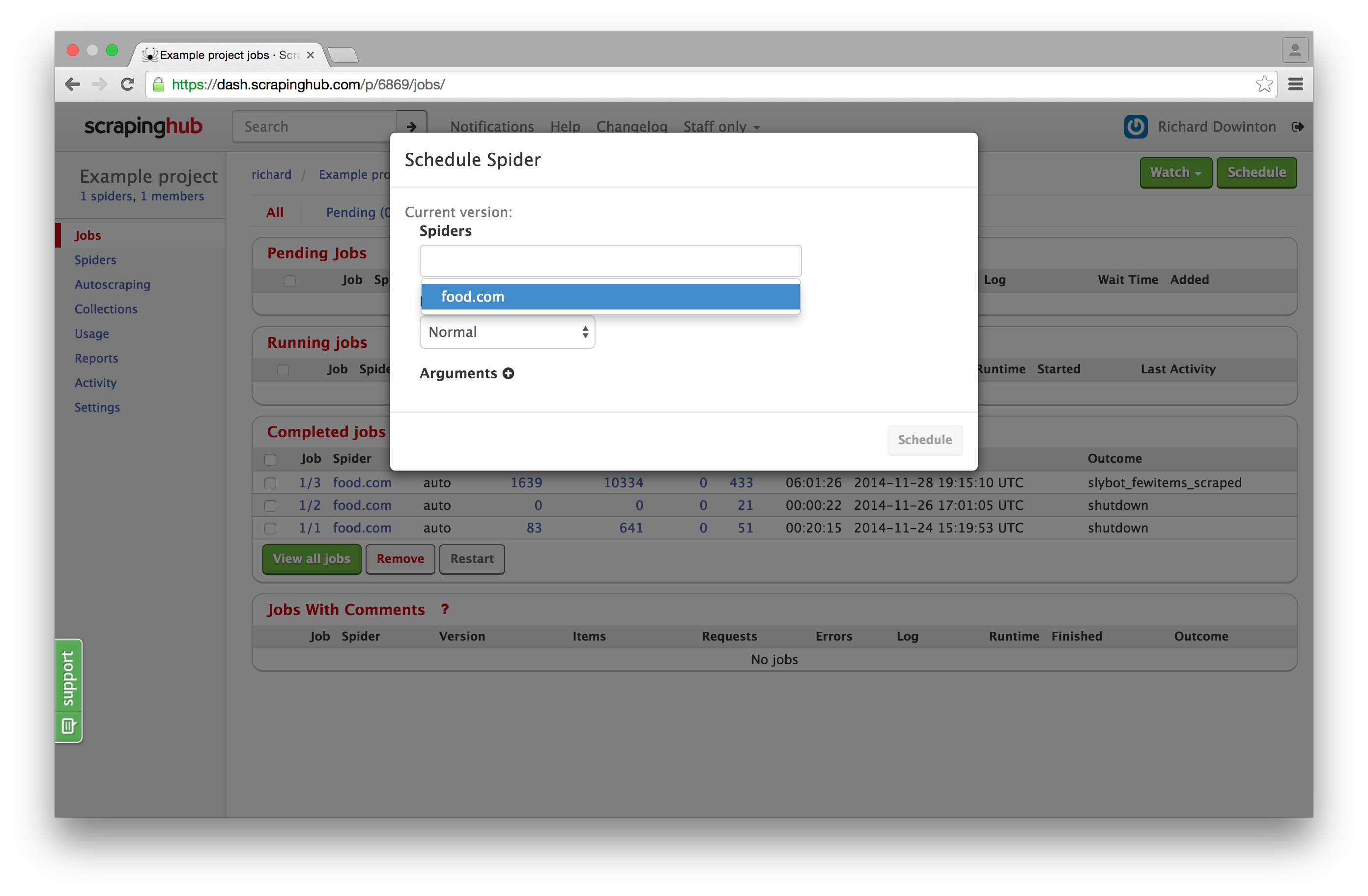
A new user interface for scheduling spiders:
And much more!
Your Organization on Scrapy Cloud
You are now able to create and manage organizations in Scrapy Cloud, add members if necessary and from there create new projects under your organization. This will make it much easier for you to manage your projects and keep them all in one place. Also, to make things simpler, our billing system will soon be managed at the organization level rather than per individual user.
You are now able to create projects within the context of an organization, however other organization members will need to be invited in order to access it. A user can be invited to a project even if that user is not a member of the project's organization.
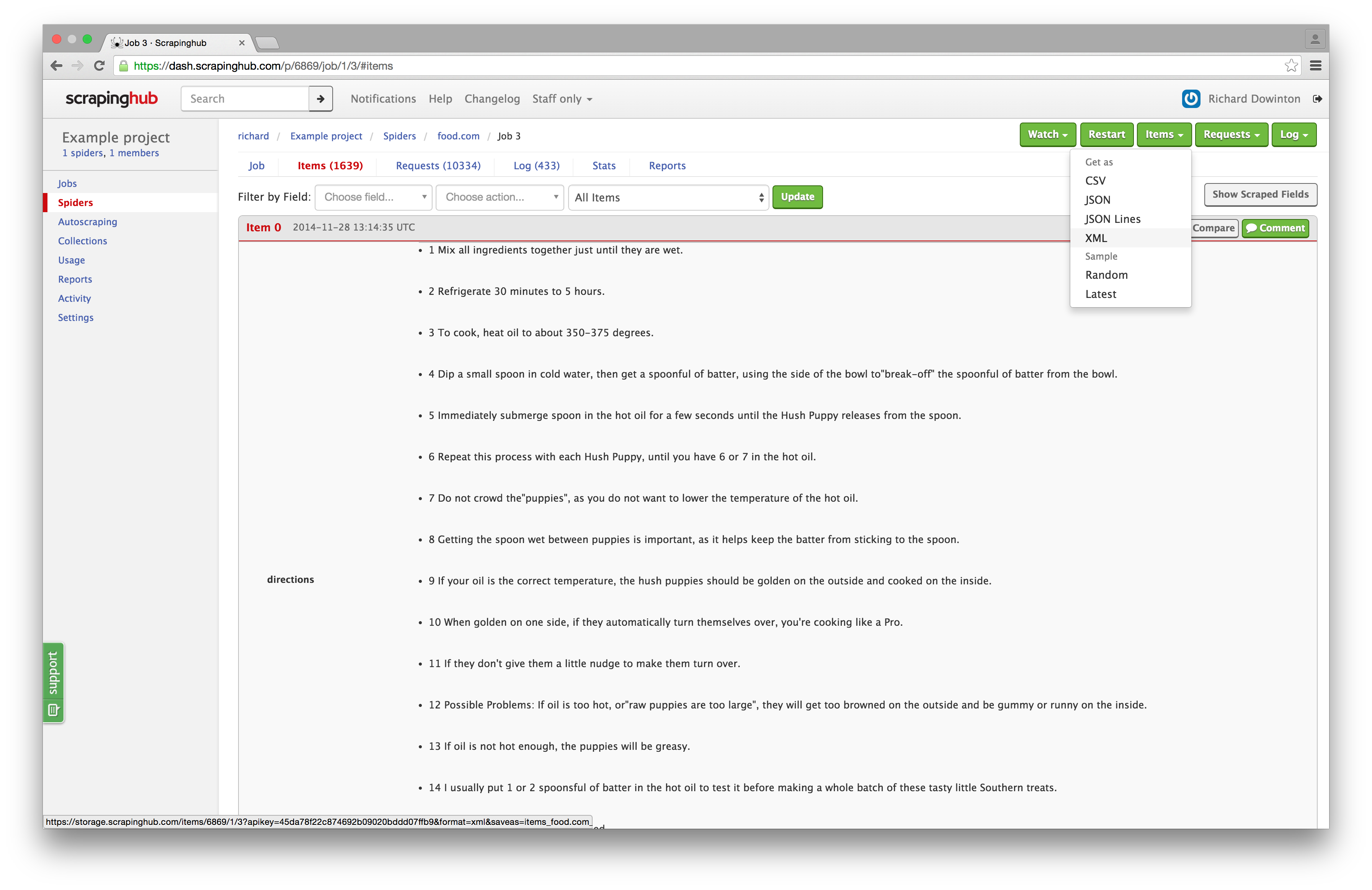
Export Items as XML
Due to popular demand, we have added the ability to download your items as XML:
Improvements to Periodic Jobs
We have made several improvements to the way periodic jobs are handled:
- There is no delay when creating or editing a job. For example, if you create a new a job at 11:59 to run at 12:00, it will do so without any trouble.
- If there is any downtime, jobs that were intended to be scheduled during the downtime will be scheduled automatically once the service is restored.
- You can now schedule jobs at specific dates in the month.
Portia Now Available in Dash
Last year, we open-sourced our annotation based scraping tool, Portia. We have since been working to integrate it into Dash, and it's finally here!
We have added an 'Open in Portia' button to your projects' Autoscraping page, so you can now open your Scrapy Cloud projects in Portia. We intend Portia to be a successor to our existing Autoscraping interface, and hope you find it to be a much more pleasant experience. No longer do you have to do a preliminary crawl to begin annotating, you can just jump straight in!
Check out this demo of how you can create a spider using Portia and Dash!
Enjoy the new features, and of course if you have any feedback please don't hesitate to post on our support forum!