Custom crawling & News API: designing a web scraping solution
Web scraping projects usually involve data extraction from many websites.
The standard approach to tackle this problem is to write some code to navigate and extract the data from each website.
However, this approach may not scale so nicely in the long-term, requiring maintenance effort for each website; it also doesn’t scale in the short-term, when we need to start the extraction process in a couple of weeks. Therefore, we need to think of different solutions, such as custom crawling to tackle these issues.
Problem formulation
The problem we propose to solve here is related to article content extraction that can be available in HTML form or files, such as PDFs.
The catch is that this is required for a few hundreds of different domains and we should be able to scale it up and down without much effort.
A brief outline of the problem that needs to be solved:
- Crawling starts on a set of input URLs for each of the target domains
- For each URL, perform a discovery routine to find new URLs
- If a URL is an HTML document, perform article content extraction
- If a URL is a file, download it to some cloud storage
- Daily crawls with only new content (need to keep track of what was seen in the past)
- Scale it in such a way that it doesn’t require a crawler per website
In terms of the solution, file downloading is already built-in Scrapy, it’s just a matter of finding the proper URLs to be downloaded. A routine for HTML article extraction is a bit more tricky, so for this one, we’ll go with Zyte’s Automatic Extraction News and Article API.
This way, we can send any URL to this service and get the content back, together with a probability score of the content being an article or not. Performing a crawl based on some set of input URLs isn’t an issue, given that we can load them from some service (AWS S3, for example).
Daily incremental crawls are a bit tricky, as it requires us to store some kind of ID about the information we’ve seen so far. The most basic ID on the web is a URL, so we just hash them to get an ID. Last but not least, building a single crawler that can handle any domain solves one scalability problem but brings another one to the table.
For example, it customer crawling, when we build a crawler for each domain, we can run them in parallel using some limited computing resources (like 1GB of RAM). However, once we put everything in a single crawler, especially the incremental crawling requirement, it requires more resources.
Consequently, it requires some architectural solutions to handle this new scalability issue if you want to secure effective custom crawling further down the road.
3 main tasks to consider:
- Load a set of input URLs and perform some discovery on them (filtering out the content we’ve already seen)
- For each one of these new URLs extract the data using Zyte Automatic Extraction API
- Or download the file.
Proposed architecture
Whether you are approaching a custom crawling solution or not. By thinking about each of these tasks separately, we can build an architectural solution that follows a producer-consumer strategy.
Basically, we have a process of finding URLs based on some inputs (producer) and two approaches for data extraction (consumer).
This way, with custom crawling, we can build these smaller processes to scale arbitrarily with small computing resources and it enables us to scale horizontally if we add or remove domains. An overview of the proposed solution is depicted below.
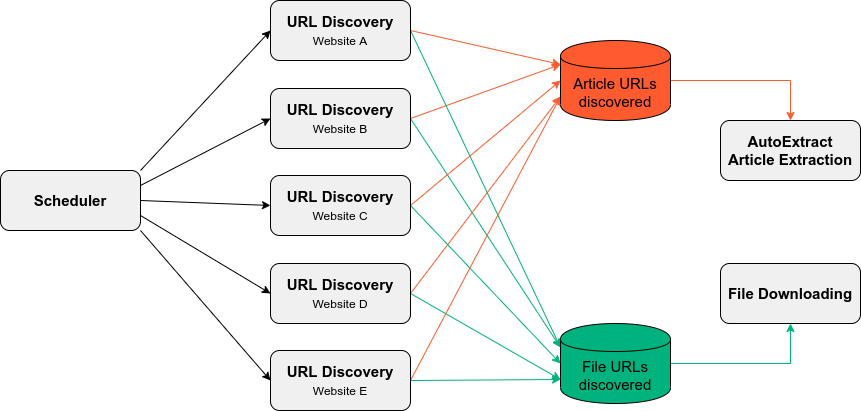
In terms of technology, this solution consists of three spiders, one for each of the tasks previously described.
This enables horizontal scaling of any of the components, but URL discovery is the one that can benefit the most from this strategy, as it is probably the most computationally expensive process in the whole solution that will end up affecting your approach to custom crawling.
The data storage for the content we’ve seen so far is performed by using Scrapy Cloud Collections (key-value databases enabled in any project) and set operations during the discovery phase. This way, content extraction only needs to get a URL and extract the content, without requiring to check if that content was already extracted or not.
Again, going back to the root problem that arises from trying this custom crawling solution is communication among processes. The common strategy to handle this is a working queue, the discovery workers find new URLs and put them in queues so they can be processed by the proper extraction worker.
A simple solution to this problem is to use Scrapy Cloud Collections as a mechanism for that. As we don’t need any kind of pull-based approach to trigger the workers, they can simply read the content from the storage.
This strategy works fine, as we are using resources already built-in inside a project in Scrapy Cloud, without requiring extra components. But always be mindful to carefully follow the steps above if you are to deploy a custom crawling solution.

At this moment, the custom crawling solution is almost complete. There is only one final detail that needs to be addressed.
This is related to computing resources. As we are talking about scalability, an educated guess is that at some point we’ll have handled some X millions of URLs, and checking if the content is new can become expensive.
This happens because we need to download the URLs we’ve seen to memory, so we avoid network calls to check if a single URL was already seen.
Though, if we keep all URLs in memory and we start many parallel discovery workers, we may process duplicates (as they won’t have the newest information in memory).
Also, keeping all those URLs in memory can become quite expensive. A solution to this issue is to perform some kind of sharding to these URLs. The awesome part about it is that we can split the URLs by their domain, so we can have a discovery worker per domain and each of them needs to only download the URLs seen from that domain.
This means we can create a collection for each one of the domains we need to process and avoid the huge amount of memory required per worker.
This overall custom crawling solution comes with a benefit that, if there’s some kind of failure, we can rerun any worker independently, without affecting others (in case one of the websites is down).
Also, with custom crawling, if we need to re-crawl a domain, we can easily clean the URLs seen in this domain and restart its worker.
All in all, breaking this complex process into smaller ones, brings lots of complexity to the table, but allows easy scalability through small independent processes.
Tooling
Even though we outlined a solution to the problem via custom crawling, we need some tools to build it.
Main tools to solve similar custom crawling problems:
- Scrapy is the go-to tool for building the three spiders used for custom crawling, in addition to scrapy-autoextract middleware to handle the communication with Zyte Automatic Extraction API.
- Scrapy Cloud Collections are an important component of the solution, they can be used through the python-scrapinghub package.
- Zyte Smart Proxy Manager can be used for proxy rotation and Splash for javascript rendering when required.
- Finally, autopager can be handy to help in automatic discovery of pagination in websites, and spider-feeder can help to handle arbitrary inputs to a given spider.
Let’s talk about your project!
With 10+ years of web data extraction experience, our team of 100+ web scraping experts has solved numerous technical challenges like this one above.
If your company needs web data, or custom crawling projects, but you don’t have the expertise in-house, reach out to us and let us handle it for you. So you can focus on what matters for you the most!