Looking back at 2017
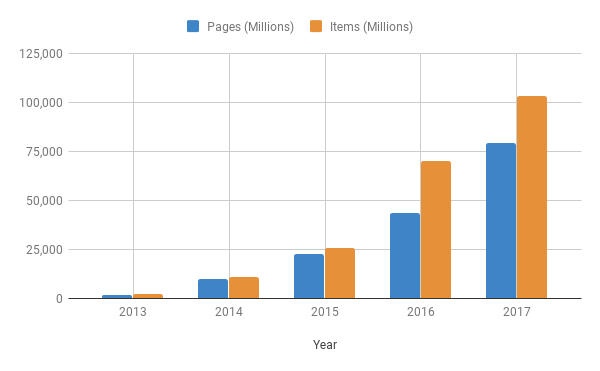
It’s been another standout year for Scrapinghub and the scraping community at large. Together we crawled 79.1 billion pages (nearly double 2016), with over 103 billion scraped records; what a year!
We’ll do our best here to give you the highlights of 2017 and whet your appetite for what you can expect in 2018 - let’s get into it:
What’s new
Let’s start with some of what was new in 2017!
In July we launched a new offering specifically for data subscriptions that we call Data on Demand. Our aim is to streamline how we deliver data solutions and create an offering that is quicker and easier for everyone. Then, we created our Enterprise Scrapy Training program. It’s everything that’s needed for teams to learn web scraping and get started with Scrapy.
We introduced a dedicated Account Management team. Perks include regular performance reviews, product sponsorship opportunities, and one-on-one project/product support for our Enterprise clients. We've invested in new programs and campaigns to better follow-up and engage with customers, provide personalized onboarding experience, and improve how we gather and act on customer feedback.
Highlights
Scrapy Cloud
In previous years we focused on the technical capabilities and improvements of the platform, like Docker support and a complete overhaul of our Scrapy Cloud architecture. While that will always be a must for us, this year we also gave more focus to usability and helping you, our customers, get more out of the platform.
First we made it easier to deploy spiders, including the ability to sync and deploy from Github repository within Scrapy Cloud. You can even sign using Github so that your spiders are ready to run right away.
Then, we took a look at improving the platform as a whole, with an updated interface that not only looks better (at least we think so!), but consumes less resources, and is faster and easier to use. The early results have been impressive and we’re just getting started!
Putting this into numbers, we duplicated the growth that we saw last year in yearly platform sign ups:
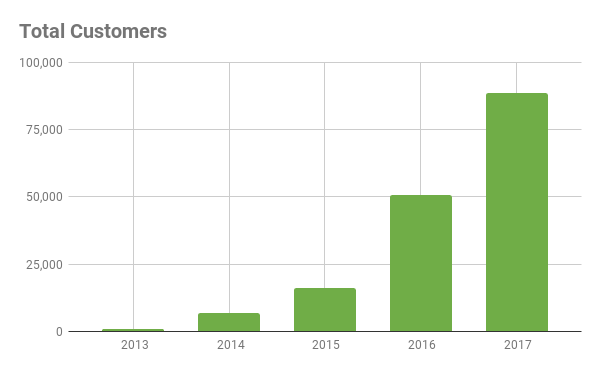
Even with this customer growth, it’s important that Scrapy Cloud continues to succeed at helping developers crawl web pages and extract items:
Smart Proxy Manager
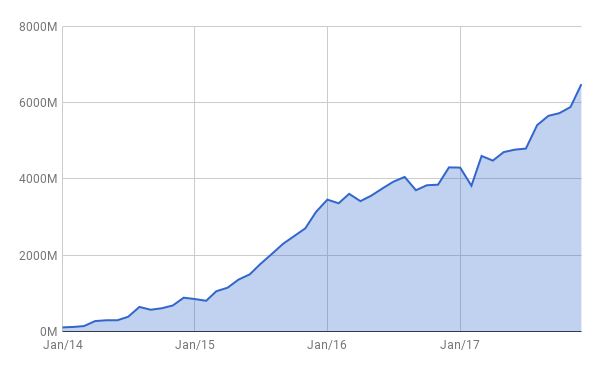
For those that require something a bit more advanced in proxy management, we continue to provide the best solution with Smart Proxy Manager , our other flagship product. Similar to Scrapy Cloud, 2017 saw numbers that exceeded any previous year (successful requests) and a growth rate that was more than double that of 2016:
Data Science
Data Science has always been part of Scrapinghub’s DNA, even if it has sometimes gone by other names. That said, we’ve been working on some interesting new projects including automated extraction, Machine Learning for data analysis, and spiders that automatically adapt to changes in websites.
Equally exciting is that most of this has been used at scale, adding real world value for our customers.
Zytan team continues to grow
2017 was the biggest year of hiring that we’ve experienced thus far, with 46 people joining the Scrapinghub family! Among other things, this means improved global sales and support coverage, and even more world-class engineers.
Oh, and we’re showing no signs of slowing - if you’re passionate about scraping, web crawling, and data science, we’re hiring!
Team get together
We had our largest Zyte get together this year! Estepona, Spain played host to over 70 Zytans (formerly Scrapinghubbers) as we got to meet each other face to face (a rare treat for a fully distributed team).
We held a town hall with updates from the year and worked on some sessions to identify our top opportunities as a company:

And of course, it wasn’t all work and no play. There was some fun (but competitive!) beach olympics, and singing/dancing the night away with karaoke:


Next Year
As we look towards 2018, we’re focused on a number of different things to continue the trend we’ve seen in the last few years. Here are just a few highlights that we’re sure you’ll love:
First, we’re working to take the learnings that we got out of simplifying the Scrapy Cloud workflows, and apply them to Crawlera. This includes better integration between our two flagship products.
At the same time, we’re improving things behind the scenes to make the entire platform faster, more stable and more efficient. That means that along with new feature development, you can expect the core Scrapinghub products to get even better.
One of the most frequent requests we receive is for a Crawlera billing model that better matches your needs - usage based rather than tied to predefined plans. We’re happy to announce that this is coming in 2018 (we're already working on it)!
Internally, we plan to continue our momentum with training and development programs and more formal career paths - something that we’ve learned becomes more important as a company grows to this size. We'll also be focused on more efficiently spreading learnings throughout the organization, especially our breakthroughs in Data Science.
Wrap Up
And that’s all for 2017! From all of us at Zyte , we sincerely wish you a happy holidays and hope you’re as excited as we are to see what 2018 holds. Oh, and we also hope that you’re able to ring in 2018 with at least this much fun:
