Scraping the Steam game store with Scrapy
This is a guest post from the folks over at Intoli, one of the awesome companies providing Scrapy commercial support and longtime Scrapy fans.
Introduction
The Steam game store is home to more than ten thousand games and just shy of four million user-submitted reviews. While all kinds of Steam data are available either through official APIs or other bulk-downloadable data dumps, I could not find a way to download the full review dataset. 1 If you want to perform your own analysis of Steam reviews, you therefore have to extract them yourself.
Doing so can be tricky if scraping is not your primary concern, however. Here's what some of the fields we are interested in look like on the page.

Even for a well-designed and well-documented project like Scrapy (my favorite Python scraper) there exists a definite gap between the getting started guide and a larger project dealing with realistic pitfalls. My goal in this guide is to help scraping beginners bridge that gap. 2
What follows is a step-by-step guide explaining how to build up the code that's in this repository, but you should be able able to jump directly into a section you're interested in.
If you are only interested in using the completed scraper, then you can head directly to the companion GitHub repository.
Setup
Before we jump into the nitty-gritty of scraper construction, here's a quick setup guide for the project. Start with setting up and initiating a virtualenv:
mkdir steam-scraper cd steam-scraper virtualenv -p python3.6 env . env/bin/activate
I decided to go with Python 3.6 but you should be able to follow along with earlier versions of Python with only minor modifications along the way.
Install the required Python packages:
pip install scrapy smart_getenv
and start a new Scrapy project in the current directory with
scrapy startproject steam .
Next, configure rate limiting so that your scrapers are well-behaved and don't get banned by generic DDoS protection by adding
AUTOTHROTTLE_ENABLED = True AUTOTHROTTLE_TARGET_CONCURRENCY = 4.0
to steam/settings.py. You can optionally set USER_AGENT to match your browser's configuration. This way the requests coming from your IP have consistent user agent strings.
Finally, turn on caching. This is always one of the first things I do during development because it enables rapid iteration and spider testing without blasting the servers with repeated requests.
HTTPCACHE_ENABLED = True HTTPCACHE_EXPIRATION_SECS = 0 # Never expire.
We will improve this caching setup a bit later.
Writing a Crawler to Find Game Data
We first write a crawler whose purpose is to discover game pages and extract useful metadata from them. Our job is made somewhat easier due to the existence of a complete product listing which can be found by heading to Steam's search page, and sorting the products by release date.
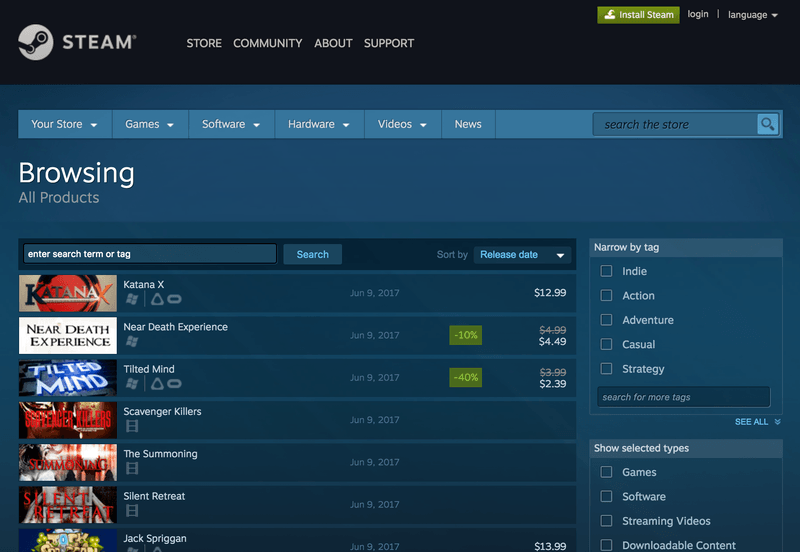
This listing is more than 30,000 pages long, so our crawler needs to be able to navigate between them in addition to following any product links. Scrapy has an existing CrawlSpider class for exactly this kind of job. The idea is that we can control the spider's behavior by specifying a few simple rules for which links to parse, and which to follow in order to find more links.
Every product has a storefront URL steampowered.com/app/<id>/ determined by its unique Steam ID. Hence, all we have to do is look for URLs matching this pattern. Using Scrapy's Rule class this can be accomplished with
Rule( LinkExtractor( allow='/app/(.+)/', restrict_css='#search_result_container' ), callback='parse_product' )
where the callback parameter indicates which function parses the response, and #search_result_container is the HTML element containing the product links.
Next, we have to make a rule that navigates between pages applies the rules recursively, since this will keep advancing the page and finding products using the previous rule. In Scrapy this is accomplished by omitting the callback parameter which by default uses the parse method of CrawlSpider.
Rule(LinkExtractor( allow='page=(d+)', restrict_css='.search_pagination_right') )
You can now place a skeleton crawler into spiders/product.py!
class ProductSpider(CrawlSpider): name = 'products' start_urls = ["http://store.steampowered.com/search/?sort_by=Released_DESC"] allowed_domains=["steampowered.com"] rules = [ Rule( LinkExtractor( allow='/app/(.+)/', restrict_css='#search_result_container'), callback='parse_product'), Rule( LinkExtractor( allow='page=(d+)', restrict_css='.search_pagination_right')) ]
def parse_product(self, response):
pass
Extracting Data from a Product Page
Next, we turn to actually extracting data from crawled product pages, i.e., implementing the parse_product method above. Before writing code, explore a few product pages such as http://store.steampowered.com/app/316790/ to get a better sense of the available data.
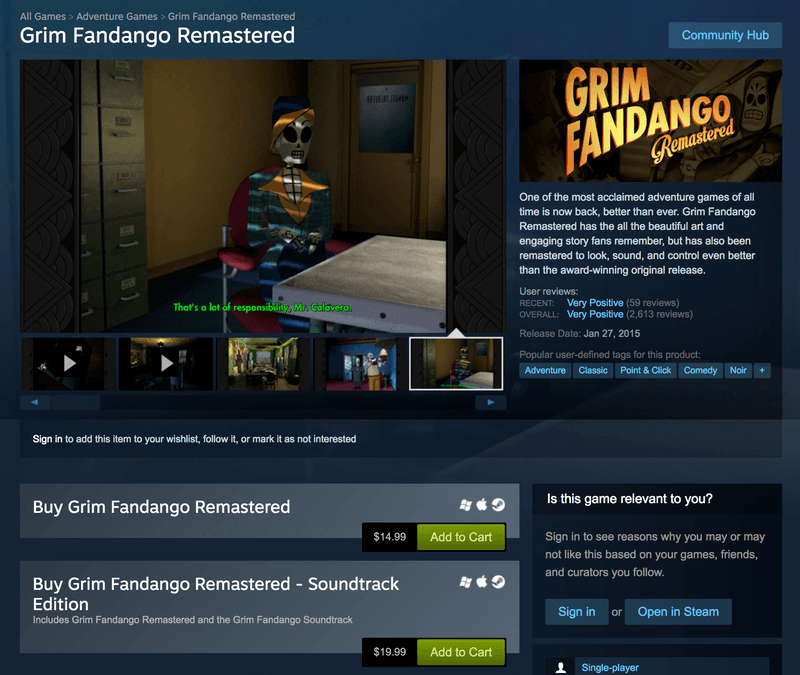
Poking around the HTML a bit, we can see that Steam developers have chosen to make ample use of narrowly-scoped CSS classes and plenty of id tags. This makes it particularly easy to target specific bits of data for extraction. Let's start by scraping the game's name and list of "specs" such as whether the game is single- or multi-player, whether it has controller support, etc.

The simplest approach is to use CSS and XPath selectors on the Response object followed by a call to .extract() or .extract_first() to access text or attributes. One of the nice things about Scrapy is the included Scrapy Shell functionality, allowing you to drop into an interactive iPython shell with a response loaded using your project's settings. Let's drop into this console to see how these selectors work.
scrapy shell http://store.steampowered.com/app/316790/
We can get the data by examining the HTML and trying out some selectors:
response.css('.apphub_AppName ::text').extract_first() # Outputs 'Grim Fandango Remastered' response.css('.game_area_details_specs a ::text').extract() # Outputs ['Single-player', 'Steam Achievements', 'Full controller support', ...]
The corresponding parse_product method might look something like:
def parse_product(self, response): return { 'app_name': response.css('.apphub_AppName ::text').extract_first(), 'specs': response.css('.game_area_details_specs a ::text').extract() }
Using Item Loaders for Cleaner Code
As we add more data to the parser, we encounter HTML that needs to be cleaned before we get something useful. For example, one way to get the number of submitted reviews is to extract all review counters (there are multiple ones on the page sometimes) and get the max. The HTML is of the form
... <span class="responsive_hidden"> (59 reviews) </span> ... <span class="responsive_hidden"> (2,613 reviews) </span> ...
which we use to write
n_reviews = response.css('.responsive_hidden').re('(([d,]+) reviews)') n_reviews = [int(r.replace(',', '')) for r in n_reviews] # [57, 2611] n_reviews = max(n_reviews) # 2611
This is a pretty mild example, but such mixing of data selection and cleaning can lead to messy code that is annoying to revisit. That is fine in small projects, but I chose to separate selection of interesting data from the page and its subsequent cleaning and normalization with the help of Item and ItemLoader abstractions.
The concept is simple: An Item is a specification of the fields your parser produces. A trivial example would be something like:
class ProductItem(scrapy.Item): app_name = scrapy.Field() specs = scrapy.Field() n_reviews = scrapy.Field() product = ProductItem() product['app_name'] = 'Grim Fandango Remastered' product['specs'] = ['Single Player', 'Steam Achievements'] product['n_reviews'] = 2611
To make this useful, we make a corresponding ItemLoader that is in charge of collecting and cleaning data on the page and passing it to the Item for storage.
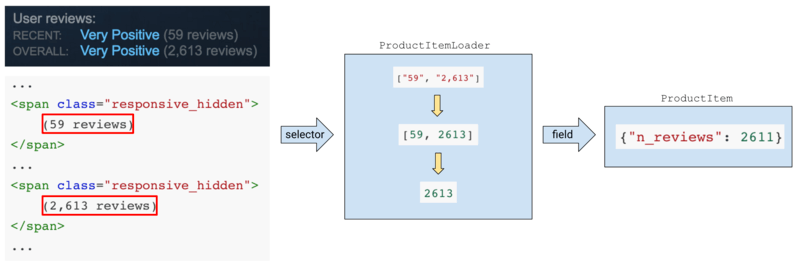
An ItemLoader collects data corresponding to a given field into an array and processes each extracted element as it's being added with an "input processor" method. The array of extracted items is then passed through an "output processor" and saved into the corresponding field. For instance, an output processor might concatenate all the entries into a single string or filter incoming items using some criterion.
Let's look at how this is handled in ProductSpider. Expand the above ProductItem in steam/items.py with some nontrivial output processors
class ProductItem(scrapy.Item): app_name = scrapy.Field() # (1) specs = scrapy.Field( output_processor=MapCompose(StripText()) # (4) ) n_reviews = scrapy.Field( output_processor=Compose( MapCompose( StripText(), lambda x: x.replace(',', ''), str_to_int), # (5) max ) )
and add a corresponding ItemLoader
class ProductItemLoader(ItemLoader): default_output_processor=TakeFirst() # (2)
These data processors can be defined within an ItemLoader, where they sit more naturally perhaps, but writing them into an Item's field declarations saves us some unnecessary typing.
To actually extract the data, we integrate these two into the parser with
from ..items import ProductItem, ProductItemLoader
def parse_product(self, response):
loader = ProductItemLoader(item=ProductItem(), response=response)
loader.add_css('app_name', '.apphub_AppName ::text') # (3)
loader.add_css('specs', '.game_area_details_specs a ::text')
loader.add_css('n_reviews', '.responsive_hidden',
re='(([d,]+) reviews)') # (6)
return loader.load_item()
Let's step through this piece by piece. Each number here corresponds to the (#) annotation in the code above.
(1) - A basic field that saves its data using the default_output_processor defined at (2). In this case, we just take the first extracted item.
(3) - Here we connect the app_name field to an actual selector with .add_css().
(4) - A field with a customized output processor. MapCompose is one of a few processors included with Scrapy in scrapy.loader.processors, and it applies its arguments to each item in the array of extracted data.
(4) and (5) - Arguments passed to MapCompose are just callables, so can be defined however you wish. Here I defined a simple string to integer converter with error handling built-in
def str_to_int(x): try: return int(float(x)) except: return x
and a text-stripping utility in which you can customize the characters being stripped (which is why it's a class)
class StripText: def __init__(self, chars=' rtn'): self.chars = chars def __call__(self, value): # This makes an instance callable! try: return value.strip(self.chars) except: return value
(6) - Notice that .add_css() can also extract regular expressions, again into a list!
This may seem like overkill, and in this example it is, but when you have a few dozen selectors, each of which needs to be cleaned and processed in a similar way, using ItemLoaders avoids repetitive code and associated mistakes. In addition, Items are easy to integrate with custom ItemPipelines, which are simple extensions for saving data streams. In this project we will be outputting line-by-line JSON (.jl) streams into files or Amazon S3 buckets, both of which are already implemented in Scrapy, so there's no need to make a custom pipeline. An item pipeline could for instance save incoming data directly into an SQL database via a Python ORM like Peewee or SQLAlchemy.
You can see a more comprehensive product item pipeline in the steam/items.py file of the accompanying repository. Before doing a final crawl of the data it's generally a good idea to test things out with a small depth limit and prototype with caching enabled. Make sure that AUTOTHROTTLE is enabled in the settings, and do a test run with
mkdir output scrapy crawl products -o output/products.jl -s DEPTH_LIMIT=2
Here's a small excerpt of what the output of this command looks like:
2017-06-10 15:33:23 [scrapy.core.scraper] DEBUG: Scraped from
{'app_name': 'Airtone',
'n_reviews': 24,
'specs': ['Single-player','Steam Achievements', ... 'Room-Scale']}
...
017-06-10 15:32:43 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to from
<span class="cm-comment"><GET http://store.steampowered.com/app/646200/Dead_Effect_2_VR/?snr=1_7_7_230_150_1></span>
Exploring this output and cross checking with the Steam store reveals a few potential issues we haven't addressed yet.
First, there is a 302 redirect that forwards us to a mature content checkpoint that needs to be addressed before Steam will allow us to see the corresponding product listing.
Second, URLs include a mysterious snr query string parameter that doesn't have a meaningful effect on page content.
Although the parameter doesn't seem to be varying too much within a short time span, it could lead to duplicated entries.
Not the end of the world, but it would be nice to take care of this before proceeding with the crawl.
Custom Request Dropping and Caching Rules
In order to avoid scraping the same URL multiple times Scrapy uses a duplication filter middleware. It works by standardizing the request and comparing it to an in-memory cache of standardized requests to see if it's already been processed.
Since URLs which differ only by the value of the snr parameter point to the same resource we want to ignore it when determining which URL to follow.
So, how is this done?
The solution is representative of the way I like to deal with custom behavior in Scrapy: read its source code, then overload a class or two with the minimal amount of code necessary to get the job done. Scrapy's source code is pretty readable, so it's easy to learn how a core component functions as long as you are familiar with the general architectural layout.
For our purposes we look through SteamDupeFilter in scrapy.dupefilters and conclude that all we have to do is overload its request_fingerprint method
from w3lib.url import url_query_cleaner from scrapy.dupefilters import RFPDupeFilter class SteamDupeFilter(RFPDupeFilter): def request_fingerprint(self, request): url = url_query_cleaner(request.url, ['snr'], remove=True) request = request.replace(url=url) return super().request_fingerprint(request)
and point the change out to Scrapy in our project's settings.py
DUPEFILTER_CLASS = 'steam.middlewares.SteamDupeFilter'
In the repository, I also update the default caching policy by overloading the _redirect method of RedirectMiddleware from scrapy.downloadermiddlewares.redirect, but you should be fine without doing so.
Next, we figure out how to deal with mature content redirects.
Getting through Access Checkpoints
Steam actually has two types of checkpoint redirects, both for the purposes of verifying the user's age before allowing access to a product page with some kind of mature content. There is another redirect, appending the product's name to the end of the URL, but it's immaterial for our purposes.
The first is a simple age input form, asking the user to explicitly input their age. For example, trying to access http://store.steampowered.com/app/9200/ redirects the user to http://store.steampowered.com/agecheck/app/9200/.
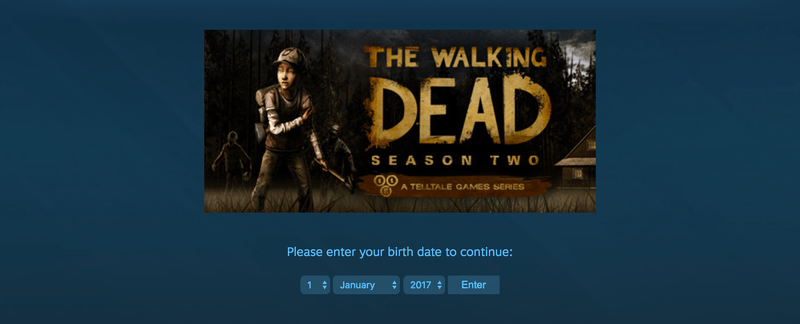
Submitting the form with a birthday sufficiently far back allows the user to access the desired resource, so all we have to do is instruct Scrapy to submit the form when this happens.
Checking out the age form's HTML reveals all the input fields whose values are submitted through the form, so we simply replicate them every time we detect the right pattern in our response URL:
def parse_product(self, response): # Circumvent age selection form. if '/agecheck/app' in response.url: logger.debug(f"Form-type age check triggered for {response.url}.") form = response.css('#agegate_box form') action = form.xpath('@action').extract_first() name = form.xpath('input/@name').extract_first() value = form.xpath('input/@value').extract_first() formdata = { name: value, 'ageDay': '1', 'ageMonth': '1', 'ageYear': '1955' } yield FormRequest( url=action, method='POST', formdata=formdata, callback=self.parse_product ) else: # I moved all parsing code into its own function for clarity. yield load_product(response)
The other type of redirect is a mature content checkpoint that requires the user to press a "Continue" button before showing the actual product page. Here's one example: http://store.steampowered.com/app/414700/.

Note that this checkpoint's URL is different than in the previous case, letting us easily distinguish between them from a spider.
By looking at the HTML, you can see that the mechanism by which access is granted to the product page is also different than last time.
Hitting "Continue" triggers a HideAgeGate JavaScript function that sets a mature_content cookie and updates the address, inducing a page reload with the new cookie present.
The routine is hard-coded on the page and the parts we care about resemble the following.
function HideAgeGate( ) {
// Set the cookie.
V_SetCookie( 'mature_content', 1, 365, '/' );
// Refresh the page.
document.location = "http://store.steampowered.com/app/414700/Outlast_2/";
}
This suggests that including a mature_content cookie with a request is sufficient to pass the checkpoint, and easily verified with
curl --cookie "mature_content=1" http://store.steampowered.com/app/414700/
So, all we have to do is include that cookie with requests to mature content restricted pages.
Luckily, Scrapy has a redirect middleware which can intercept redirect requests and modify them on the fly. As usual, we observe the source and notice that the only method we need to change is RedirectMiddleware._redirect() (and only slightly).
In steam/middlewares.py, add the following
from scrapy.downloadermiddlewares.redirect import RedirectMiddleware class CircumventAgeCheckMiddleware(RedirectMiddleware): def _redirect(self, redirected, request, spider, reason): # Only overrule the default redirect behavior # in the case of mature content checkpoints. if not re.findall('app/(.*)/agecheck', redirected.url): return super()._redirect(redirected, request, spider, reason) logger.debug(f"Button-type age check triggered for {request.url}.") return Request(url=request.url, cookies={'mature_content': '1'}, meta={'dont_cache': True}, callback=spider.parse_product)
We could have alternatively added a mature_content cookie to all requests by modifying the CookiesMiddleware, or just passed it into the initial request. Note also that overloading redirects like this is the first step in handling captchas and more complex gateways, as explained in this advanced scraping tutorial by Intoli's own Evan Sangaline.
This basically covers the crawler and all gotchas encountered... all that's left to do is run it. The run command is similar to the one given above, except that we want to remove the depth limit, disable caching, and perhaps keep a job file in order to enable resuming in case of an interruption (the job takes a few hours):
scrapy crawl products -o output/products_all.jl --logfile=output/products_all.log --loglevel=INFO -s JOBDIR=output/products_all_job -s HTTPCACHE_ENABLED=False
When the crawl completes, we will hopefully have metadata for all games on Steam in the output file output/products_all.jl . Example output from the completed crawler that is available in the accompanying repository looks like this:
{
'app_name': 'Cold Fear™',
'developer': 'Darkworks',
'early_access': False,
'genres': ['Action'],
'id': '15270',
'metascore': 66,
'n_reviews': 172,
'price': 9.99,
'publisher': 'Ubisoft',
'release_date': '2005-03-28',
'reviews_url': 'http://steamcommunity.com/app/15270/reviews/?browsefilter=mostrecent&amp;p=1',
'sentiment': 'Very Positive',
'specs': ['Single-player'],
'tags': ['Horror', 'Action', 'Survival Horror', 'Zombies', 'Third Person', 'Third-Person Shooter'],
'title': 'Cold Fear™',
'url': 'http://store.steampowered.com/app/15270/Cold_Fear/'
}
Note that the output contains a manually created reviews_url field. We will use it in the next section to generate a list of starting URLs for the review scraper.
Handling Infinite Scroll to Scrape Reviews
Since product pages display only a few select reviews we need to scrape them from the Steam Community portal which contains the whole dataset.
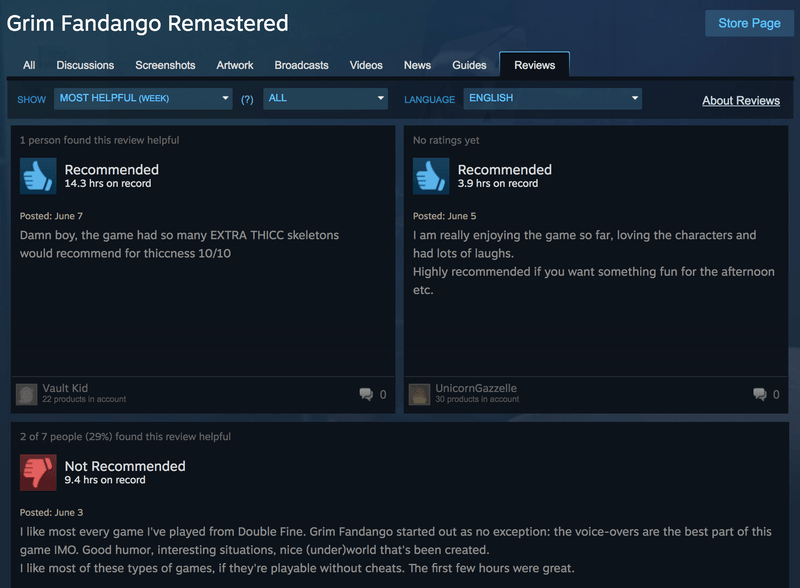
Addresses on Steam Community are determined by Steam product IDs, so we can easily generate a list of URLs to process from the output file generated by the product crawl:
http://steamcommunity.com/app/316790/reviews/?browsefilter=mostrecent&p=1 http://steamcommunity.com/app/207610/reviews/?browsefilter=mostrecent&p=1 http://steamcommunity.com/app/414700/reviews/?browsefilter=mostrecent&p=1 ...
Due to the size of the dataset you'll probably want to split up the whole list into several text files, and have the review spider accept the file through the command line:
class ReviewSpider(scrapy.Spider): name = 'reviews' def __init__(self, url_file, *args, **kwargs): super().__init__(*args, **kwargs) self.url_file = url_file
def start_requests(self):
with open(self.url_file, 'r') as f:
for url in f:
yield scrapy.Request(url, callback=self.parse)
def parse(self, response):
pass
Reviews on each page are loaded dynamically as the user scrolls down using an "infinite scroll" design. We need to figure out how this is implemented in order to scrape data from the page, so pull up Chrome's console and monitor XHR traffic while scrolling.
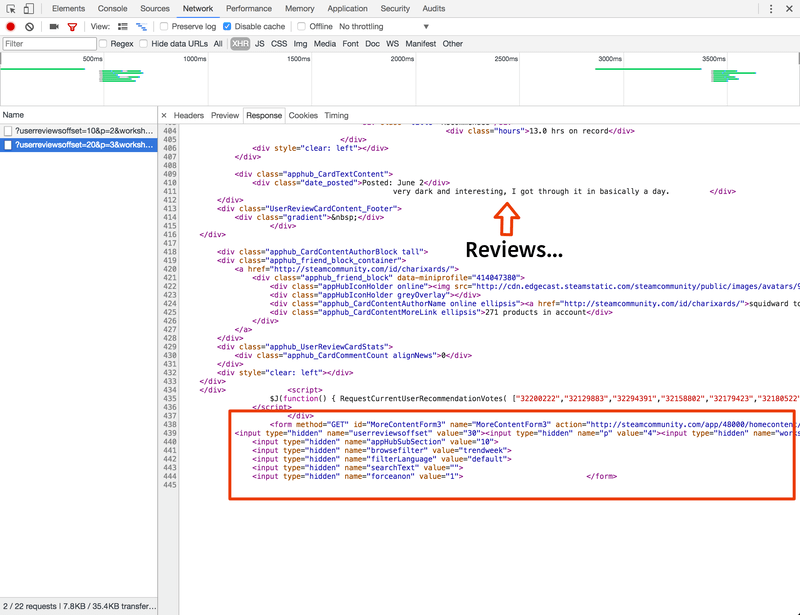
The reviews are returned as pre-rendered HTML ready to be injected into the page by JavaScript. At the bottom of each HTML response is a form named GetMoreContentForm whose purpose is clearly to get the next page of reviews. You can therefore repeatedly submit the form and scrape the response until reviews run out:
def parse(self, response): product_id = get_product_id(response) # Load all reviews on current page. reviews = response.css('div .apphub_Card') for i, review in enumerate(reviews): yield load_review(review, product_id) # Navigate to next page. form = response.xpath('//form[contains(@id, "MoreContentForm")]') if form: yield self.process_pagination_form(form, product_id)
Here load_review() returns a loaded item populated as before, and process_pagination_form parses the form and returns a FormRequest.
And that's basically it! All that's left is to run the crawl. Since the job is so large, you should probably split up the URLs between a few text files and run each on a separate box with a command like the following:
scrapy crawl reviews -o reviews_slice_1.jl -a url_file=url_slice_1.txt -s JOBDIR=output/reviews_1
The completed crawler, which you can find in the accompanying repo, produces entries like this:
{
'date': '2017-06-04',
'early_access': False,
'found_funny': 5,
'found_helpful': 0,
'found_unhelpful': 1,
'hours': 9.8,
'page': 3,
'page_order': 7,
'product_id': '414700',
'products': 179,
'recommended': True,
'text': '3 spooky 5 me',
'user_id': '76561198116659822',
'username': 'Fowler'
}
Conclusion
I hope you enjoyed this relatively detailed guide to getting started with Scrapy. Even if you are not directly interested in the Steam review dataset, we've covered more than just how to make selectors and developed practical solutions to a number of common scenarios such as redirect and infinite scroll scraping.
Leave a comment on this reddit thread.
1. This paper discusses sentiment analysis of Steam reviews, but the dataset is not available for download.
2. Steam has generally been very friendly to scrapers. They have no robots.txt restrictions, and there are multiple projects based on analyzing Steam data.