Looking back at 2016

We started 2016 with an eye on blowing 2015 out of the water. Mission accomplished.
Together with our users, we crawled more in 2016 than the rest of Zyte’s history combined: a whopping 43.7 billion web pages, resulting in 70.3 billion scraped records! Great work everyone!
In the what follows, we’ll give you a whirlwind tour of what we’ve been up to in 2016, along with a quick peek at what you can expect in 2017.
Platform
Scrapy Cloud
It’s been a great year for Scrapy Cloud as we wrap up with a massive growth in our yearly platform signups:
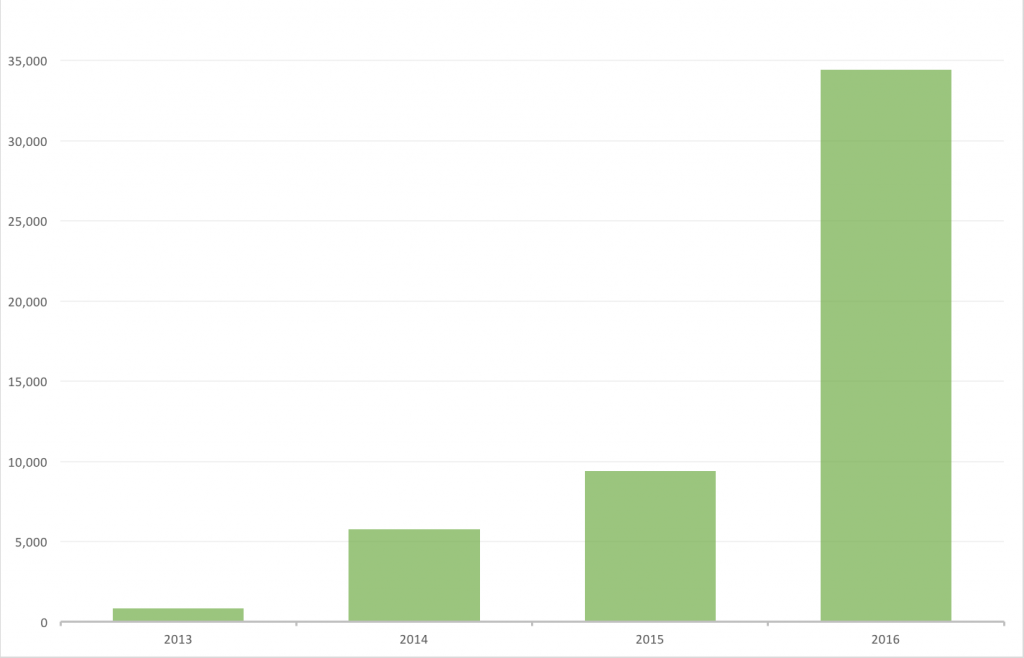
We proudly announced our biggest platform upgrade to date this year with the launch of Scrapy Cloud 2.0. Alongside technical improvements like Docker support and Python 3 support, this upgrade introduced an improved pricing model that is both less expensive for you while allowing you to better customize Scrapy Cloud based on your resource needs.
As we move into 2017, we will continue to focus on expanding the technical capabilities of our platform such as:
- Support for non-Scrapy spiders: We’re well aware that there are alternatives to Scrapy in the wild. If you’ve got a crawler created using another framework, be it in Python or another language, you’ll soon be able to run it in our cloud-based platform.
- GitHub integration: You’ll soon be able to sign up and easily deploy from GitHub. We’ll support automatic deploys shortly after: push an update to your GitHub repo and it will automatically be reflected within Zyte.
Heads up, Scrapy Cloud is in for a massive change this year, so stay tuned!
Smart Proxy Manager
Smart Proxy Manager is our other flagship product and it basically helps your crawls continue uninterrupted. We were thrilled to launch our Smart Proxy Manager Dashboard this year, which gives you the ability to visualize how you are using the product, to examine what sites and specific URLs you are targeting, and to manage multiple accounts.
Portia
The main goal of Portia is to lower the barrier of entry to web data extraction and to increase the democratization of data (it’s open source!).
Portia got a lot of love this year with the beta release of Portia 2.0. This 2.0 update includes new features like simple extraction of repeated data, loading start urls from a feed, the option to download Portia projects as python code, and the use of CSS selectors to extract specific data.
Next year we're going to be bringing a host of new features that will make Portia an even more valuable tool for developers and non-developers alike.
Data Science
While we had been engaging in data science activities since our earliest days, 2016 saw us formalize a Data Science team proper. We’re continuing to push the envelope for machine learning data extraction, so get pumped for some really exciting developments in 2017!
Open Source
Zyte has been as committed to open source as ever in 2016. Running Zyte relies on a lot of open source software so we do our best to pay it forward by providing high quality and useful software to the world. Since nearly 40 open source projects maintained by Zyte staff saw new releases this year, we’ll just give you the key highlights.
Scrapy
Scrapy is the most well-known project that we maintain and 2016 saw our first Python 3 compatible version (version 1.1) back in May (running it on Windows is still a challenge, we know, but bear with us). Scrapy is now the 11th most starred Python project on GitHub! 2017 should see it get many new features to keep it the best tool you have (we think) to tackle any web scraping project, so keep sending it some GitHub star love and feature requests!
Splash
Splash, our headless browser with an HTTP interface, hit a major milestone a few weeks ago with the addition of the long-awaited web scraping helpers: CSS selectors, form filling, interacting with DOM nodes… This 2.3 release came after a steady series of improvements and a successful Google Summer of Code (GSoC) project this summer by our student Michael Manukyan.
Dateparser
Our “little” library to help with dates in natural language got a bit of attention on GitHub when it was picked up as a dependency for Kenneth Reitz’ latest project, Maya. We’re quite proud of this little library :). Keep the bug reports coming if you find any, and if you can, please help us support even more languages.
Frontera
Frontera is the framework we built to allow you to implement distributed crawlers in Python. It provides scaling primitives and crawl frontier capabilities. 2016 brought us 11 releases including support for Python 3! A huge thank you to Preetwinder Bath, one of our GSoC students, who helped us to improve test coverage and made sure that all of the parts of Frontera support Python 3.
Google Summer of Code
As in 2014 and 2015, Zyte participated in GSoC 2016 under the Python Software Foundation umbrella. We had four students complete their projects and two of them got their contribution merged into the respective code base (see the “Frontera” and “Splash” sections above). Another completed project was related to Scrapy performance improvements and is close to being integrated. The last one is a standalone set of helpers to use Scrapy with other programming languages. To our students, Aron, Preet, Michael, and Avishkar, thank you all very much for your contributions!
Conferences
Conferences are always a great opportunity to learn new skills, showcase our projects, and, of course, hang out with our clients, users, and coworkers. As a remote staff, we don't have the opportunity to meet each other in person often, so tech conferences are always a great way to strengthen ties. The traveling Zytebers thoroughly enjoyed sharing their knowledge and web scraping experiences through presentations, tutorials, and workshops.
Check out some of the talks that were given this year:
- Cut your losses! How to use web scraping to analyse Ireland's used car market by Ruairi Fahy at PyCon Ireland
- Automatic resolution of false positives in Avast antivirus by Alexander Sibiryakov at PyCon Russia 2016
- Embedding scripts or macros inside web apps by Konstantin Lopukhin at PyCon Russia 2016
- Frontera: open source, large scale web crawling framework by Alexander Sibiryakov at PyData Berlin 2016
- How to merge noisy datasets by Johannes Ahimann at PyCon Ireland
Zytan (formerly Zyteber) Community
Being a fully remote company, we’re thrilled to confirm that we have Zytans (formerly Zytebers) in almost every continent (we’re *just* missing Antarctica, any Scrapy hackers out there?).
Aside from the conferences we attended this year, we had a few localized team retreats. The Professional Service managers got together in Bangkok, Thailand; the Sales team had a retreat in Buenos Aires, Argentina, where asado dominated the show; and the Uruguayan Zytebers got together for an end-of-year meetup in La Paloma, Uruguay, hosted by Daniel, our resident hacker/surfer.


Currently our Smart Proxy Manager team is having a meetup in Poznan, Poland, paving the way for what will become the next version of our flagship smart downloader product.
Wrap Up
And that’s it for 2016! From the whole team at Zyte , I’d like to wish you happy holidays and the best wishes for the start of 2017. We’ve got a lot of exciting events lined up next year, so get ready!