Incremental crawls with Scrapy and DeltaFetch
Welcome to Scrapy Tips from the Pros! In this monthly column, we share a few tricks and hacks to help speed up your web scraping activities. As the lead Scrapy maintainers, we’ve run into every obstacle you can imagine so don’t worry, you’re in great hands. Feel free to reach out to us on Twitter or Facebook with any suggestions for future topics.

Scrapy is designed to be extensible and loosely coupled with its components. You can easily extend Scrapy’s functionality with your own middleware or pipeline.
This makes it easy for the Scrapy community to easily develop new plugins to improve upon existing functionality, without making changes to Scrapy itself.
In this post we’ll show how you can leverage the DeltaFetch plugin to run incremental crawls.
Incremental Crawls
Some crawlers we develop are designed to crawl and fetch the data we need only once. On the other hand, many crawlers have to run periodically in order to keep our datasets up-to-date.
In many of these periodic crawlers, we’re only interested in new pages included since the last crawl. For example, we have a crawler that scrapes articles from a bunch of online media outlets. The spiders are executed once a day and they first retrieve article URLs from pre-defined index pages. Then they extract the title, author, date and content from each article. This approach often leads to many duplicate results and an increasing number of requests each time we run the crawler.
Fortunately, we are not the first ones to have this issue. The community already has a solution: the scrapy-deltafetch plugin. You can use this plugin for incremental (delta) crawls. DeltaFetch's main purpose is to avoid requesting pages that have been already scraped before, even if it happened in a previous execution. It will only make requests to pages where no items were extracted before, to URLs from the spiders' start_urls attribute or requests generated in the spiders' start_requests method.
DeltaFetch works by intercepting every Item and Request objects generated in spider callbacks. For Items, it computes the related request identifier (a.k.a. fingerprint) and stores it into a local database. For Requests, Deltafetch computes the request fingerprint and drops the request if it already exists in the database.
Now let's see how to set up Deltafetch for your Scrapy spiders.
Getting Started with DeltaFetch
First, install DeltaFetch using pip:
$ pip install scrapy-deltafetch
Then, you have to enable it in your project's settings.py file:
SPIDER_MIDDLEWARES = {
'scrapy_deltafetch.DeltaFetch': 100,
}
DELTAFETCH_ENABLED = True
DeltaFetch in Action
This crawler has a spider that crawls books.toscrape.com. It navigates through all the listing pages and visits every book details page to fetch some data like book title, description and category. The crawler is executed once a day in order to capture new books that are included in the catalogue. There's no need to revisit book pages that have already been scraped, because the data collected by the spider typically doesn't change.
To see Deltafetch in action, clone this repository, which has DeltaFetch already enabled in settings.py, and then run:
$ scrapy crawl toscrape
Wait until it finishes and then take a look at the stats that Scrapy logged at the end:
2016-07-19 10:17:53 [scrapy] INFO: Dumping Scrapy stats:
{
'deltafetch/stored': 1000,
...
'downloader/request_count': 1051,
...
'item_scraped_count': 1000,
}
Among other things, you'll see that the spider did 1051 requests to scrape 1000 items and that DeltaFetch stored 1000 request fingerprints. This means that only 51 page requests haven't generated items and so they will be revisited next time.
Now, run the spider again and you'll see a lot of log messages like this:
2016-07-19 10:47:10 [toscrape] INFO: Ignoring already visited: <GET http://books.toscrape.com/....../index.html>
And in the stats you'll see that 1000 requests were skipped because items have been scraped from those pages in a previous crawl. Now the spider hasn't extracted any items and it did only 51 requests, all of them to listing pages from where no items have been scraped before:
2016-07-19 10:47:10 [scrapy] INFO: Dumping Scrapy stats:
{
'deltafetch/skipped': 1000,
...
'downloader/request_count': 51,
}
Changing the Database Key
By default, DeltaFetch uses a request fingerprint to tell requests apart. This fingerprint is a hash computed based on the canonical URL, HTTP method and request body.
Some websites have several URLs for the same data. For example, an e-commerce site could have the following URLs pointing to a single product:
- www.example.com/product?id=123
- www.example.com/deals?id=123
- www.example.com/category/keyboards?id=123
- www.example.com/category/gaming?id=123
Request fingerprints aren’t suitable in these situations as the canonical URL will differ despite the item being the same. In this example, we could use the product’s ID as the DeltaFetch key.
DeltaFetch allows us to define custom keys by passing a meta parameter named deltafetch_key when initializing the Request:
from w3lib.url import url_query_parameter
...
def parse(self, response):
...
for product_url in response.css('a.product_listing'):
yield Request(
product_url,
meta={'deltafetch_key': url_query_parameter(product_url, 'id')},
callback=self.parse_product_page
)
...
This way, DeltaFetch will ignore requests to duplicate pages even if they have different URLs.
Resetting DeltaFetch
If you want to re-scrape pages, you can reset the DeltaFetch cache by passing the deltafetch_reset argument to your spider:
$ scrapy crawl example -a deltafetch_reset=1
Using DeltaFetch on Scrapy Cloud
You can also use DeltaFetch in your spiders running on Scrapy Cloud. You just have to enable the DeltaFetch and DotScrapy Persistence addons in your project's Addons page. The latter is required to allow your crawler to access the .scrapy folder, where DeltaFetch stores its database.
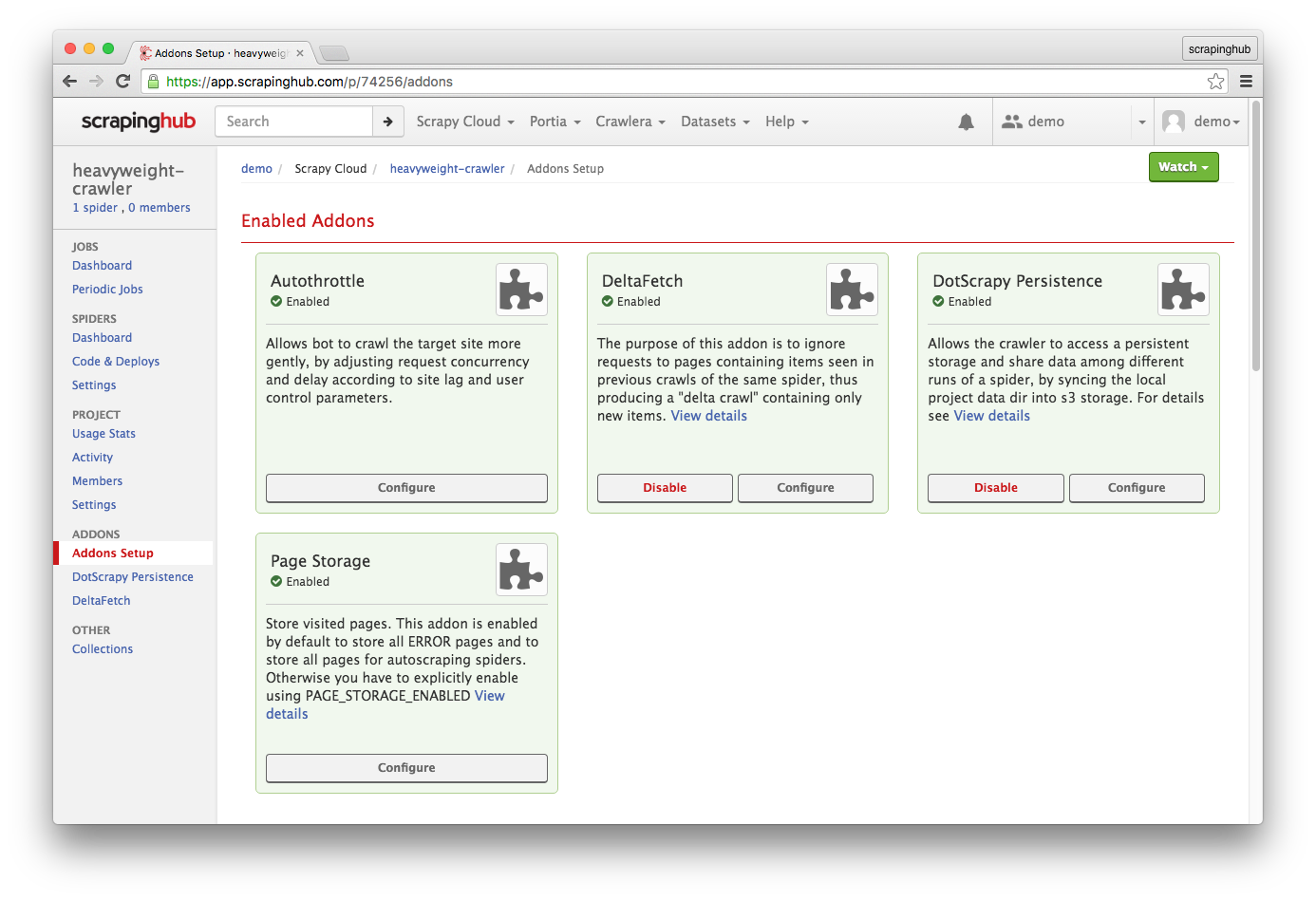
Deltafetch is quite handy in situations as the ones we’ve just seen. Keep in mind that Deltafetch only avoid sending requests to pages that have generated scraped items before, and only if these requests were not generated from the spider's start_urls or start_requests. Pages from where no items were directly scraped will still be crawled every time you run your spiders.
You can check out the project page on github for further information: http://github.com/scrapy-plugins/scrapy-deltafetch
Wrap-up
You can find many interesting Scrapy plugins in the scrapy-plugins page on Github and you can also contribute to the community by including your own plugin there.
If you have a question or a topic that you'd like to see in this monthly column, please drop a comment here letting us know or reach us out via @ZyteData on Twitter.