Introducing Scrapy Cloud 2.0
Scrapy Cloud has been with Zyte since the beginning, but we decided some spring cleaning was in order. To that end, we’re proud to announce Scrapy Cloud 2.0!
This overhaul will help you improve and scale your web scraping projects. Among other perks, our upgraded cloud-based platform includes a brand new and much more flexible architecture based on containers.
While much of this upgrade is behind the scenes, what’s most important to you is pricing changes, the introduction of Docker support, and a more efficient allocation of resources.
Without further ado, let’s dive right into how Scrapy Cloud 2.0 will positively (hopefully) affect you!
What’s NOT Changing
I know this is a weird one to start with, but we wanted to show you how the awesome base of Scrapy Cloud 1.0 will still be a part of the 2.0 release. You will still be able to:
- Deploy and schedule your spiders
- Download your results in friendly formats such as CSV and JSON
- Monitor your crawls and view logs and results in a clean, easy-to-use UI
- Use our Portia integration to scrape data straight from your web browser
- Configure Machine Learning addons like MonkeyLearn for extra functionality
And the major feature that is NOT changing is that you can still use Scrapy Cloud for free with all the perks that you've been enjoying including unlimited team members, unlimited projects, and no credit card required.
So for those who are worried, rest assured, this is just an improvement on the awesome base that made Scrapy Cloud a staple of Zyte.
New Pricing Model
First things first, the price tag. A major benefit of Scrapy Cloud 2.0 is our new pricing model. We’re switching to customizable subscriptions so that you have greater flexibility in picking the number of container units (computing resources) that you need to run your job. There are no more standardized plans, you just build a subscription that is customized to you. Plus, this model will save you money since you can tailor monthly units to your scraping needs.
Each Container Unit provides 1GB of RAM, 2.5GB of disk space and computing power that is 3x better if compared with similar plans from Scrapy Cloud 1.0. One unit costs $9 per month and you can purchase as many units as you like, allocate them for your organization's spiders and upgrade whenever you want.
When you sign up for our platform, you are immediately enrolled in a free subscription that contains 1 unit. Each job running on this free account will be able to run for up to 24 hours and has a data retention of 7 days.
And much as we love talking with our customers, Scrapy Cloud 2.0 makes upgrading your account easier and without needing to go through support. All you have to do is go to the Billing Portal for your organization (accessible via the billing page of your organization profile):

And then change the amount of Container Units to fit your needs, as shown in the screenshot below:
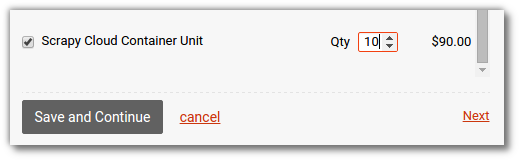
Once you purchase container units, your data retention period will be increased to 120 days and there will be no more limits to the running time.
Resource Allocation
Scrapy Cloud 2.0 features a new resource management model which provides you with more resources for the same price. For example, using Scrapy Cloud 1.0 would cost $150 for a worker with 3.45GB of RAM and 7 computing units. With Scrapy Cloud 2.0, you get 16GB of RAM and 12 computing units for a lower price ($144).
Plus, you can allocate your units (resources) however you need. This includes giving a lot of resources to big, complex jobs and making sure smaller jobs only use the resources they need.
You can assign units to groups and then move your projects from one group to another whenever you want to adjust resources:

With this new release, your spiders run in containers isolated from the other jobs running on our platform. This means that your performance will not be affected by other resource consuming jobs. Disk quotas are also applied to ensure that a job does not consume all the disk space from a server, which would affect other jobs running on the same server. Long story short, no more DoS!
Docker Support
With Scrapy Cloud 2.0, your spiders run inside Docker containers. This new resource management engine ensures that you get the most out of the resources available for your subscription.
Scrapy Cloud 2.0 is fully backwards compatible with the previous version. We did our best to keep your current workflow untouched, so you can still use the shub command line tool to deploy your project and dependencies without the hassle of building Docker images. Just make sure to upgrade shub to version 2.1.1+ by running: pip install shub --upgrade.
And here's some good news for power users: you can deploy your tailor-made Docker images to Scrapy Cloud 2.0. Dependencies are no longer a big deal since you can now compile libraries, install anything you want in your Docker image and then deploy it to our platform. This feature is currently only available for paying customers, but it will soon be released for free users as well.
Check out this walkthrough if you are a paying user and want to deploy custom Docker images to Scrapy Cloud.
Scrapy Cloud Stacks
Scrapy Cloud 2.0 introduces Stacks, a set of predefined Docker images that users can select when deploying a project. The inclusion of Stacks brings together the best of two worlds: you can deploy your project without having to build your own image and you can also choose the kind of environment where you want to run your project.
In Scrapy Cloud terms, a Stack is a pre-built Docker image that you can select when you are deploying a project. This will be used as the environment for this project. In this first release, there are two Stacks available:
- Hworker: this is the Stack that's going to be used if you just run a regular shub deploy. It provides backwards compatibility with the legacy platform, so your current projects should run without any issues.
- Scrapy: this is a minimalist Stack featuring the latest stable versions of Scrapy along with all the basic requirements that you need to run a full featured Scrapy spider. You can choose this Stack if you're having issues with outdated packages in your projects.
This is a Zyte.yml file example, using the Scrapy 1.1 Stack and passing additional requirements to be installed on the image via requirements.txt:
projects: default: 123 stacks: default: scrapy:1.1 requirements_file: requirements.txt
Just make sure that you are using shub >= 2.1.1 to be able to deploy your project based on the Zyte.yml file above.
In the near future, we are going to provide additional Stacks. For example, if you want to run a crawler that you built using a different crawling framework or programming language, we are looking to have a built-in Stack for that.
Heads Up Developers
There are some things that you should be aware of before migrating your projects to Scrapy Cloud 2.0:
- Your spiders will now run from Germany. That means their requests will no longer go through US IP addresses. If your requests are getting redirected to a localized version of a website that breaks your spiders, consider using Zyte Smart Proxy Manager . It is our smart proxy service that allows you to use location-based IPs in your crawlers, among other features.
- Spiders can no longer write arbitrary data in the project folder. You must write to the /scrapy/ folder instead. This is the current directory for spiders running in Scrapy Cloud 2.0.
- When you update your eggs, you must now also re-deploy your project. However, you can handle your dependencies using requirements.txt, which will be the only way to do this in the the future.
- Your job can’t write millions of files to the disk because there are limited disk quotas per job (256k inodes). If you need to save large amounts of data, consider using an external storage such as S3.
Check out this walkthrough if you are a paying user and want to deploy custom Docker images to Scrapy Cloud.
Roll Out Timeline
Scrapy Cloud 2.0 is officially live. From today onward, the old model will not be available to new users and all free organizations will be migrated automatically.
All Scrapy Cloud projects will be upgraded to Scrapy Cloud 2.0 within the year. As a loyal customer, you have the opportunity to upgrade immediately to experience dramatically improved performance. Just log into your Scrapy Cloud account and click the "Migrate Now" button at the top of the page:

Wrap Up
And that’s Scrapy Cloud 2.0 in a nutshell! We’re going to be tinkering a bit more in the coming months so keep your eyes peeled for an even more major upgrade.