Scraping websites based on ViewStates with Scrapy

Welcome to the April Edition of Scrapy Tips from the Pros. Each month we’ll release a few tricks and hacks that we’ve developed to help make your Scrapy workflow go more smoothly.
This month we only have one tip for you, but it’s a doozy! So if you ever find yourself scraping an ASP.Net page where you need to submit data through a form, step back and read this post.
Dealing with ASP.Net Pages, PostBacks and View States
Websites built using ASP.Net technologies are typically a nightmare for web scraping developers, mostly due to the way they handle forms.
These types of websites usually send state data in requests and responses in order to keep track of the client's UI state. Think about those websites where you register by going through many pages while filling your data in HTML forms. An ASP.Net website would typically store the data that you filled out in the previous pages in a hidden field called "__VIEWSTATE" which contains a huge string like the one shown below:

I'm not kidding, it's huge! (dozens of kB sometimes)
This is a Base64 encoded string representing the client UI state and contains the values from the form. This setup is particularly common for web applications where user actions in forms trigger POST requests back to the server to fetch data for other fields.
The __VIEWSTATE field is passed around with each POST request that the browser makes to the server. The server then decodes and loads the client's UI state from this data, performs some processing, computes the value for the new view state based on the new values and renders the resulting page with the new view state as a hidden field.
If the __VIEWSTATE is not sent back to the server, you are probably going to see a blank form as a result because the server completely lost the client’s UI state. So, in order to crawl pages resulting from forms like this, you have to make sure that your crawler is sending this state data with its requests, otherwise the page will not load what it's expected to load.
Here’s a concrete example so that you can see firsthand how to handle these types of situations.
Scraping a Website Based on ViewState
The scraping guinea pig today is quotes.toscrape.com/search.aspx. This website lists quotes from famous people and its search page allows you to filter quotes by author and tag:
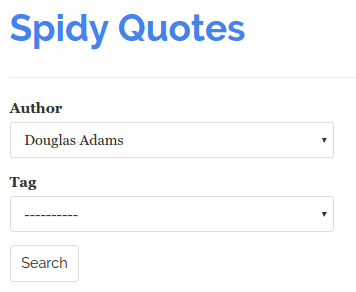
A change in the Author field fires up a POST request to the server to fill the Tag select box with the tags that are related to the selected author. Clicking Search brings up any quotes that fit the tag from the selected author:
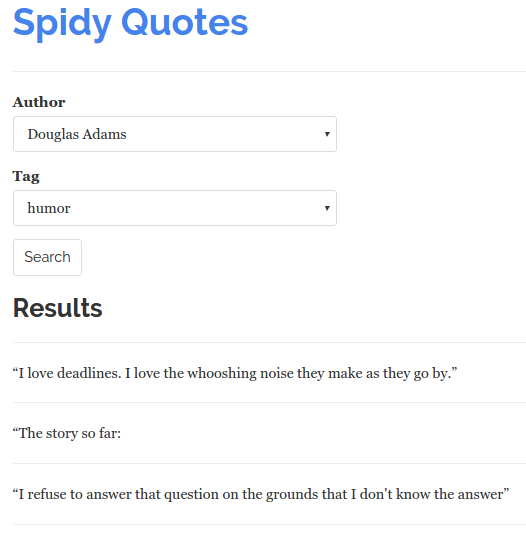
In order to scrape these quotes, our spider has to simulate the user interaction of selecting an author, a tag and submitting the form. Take a closer look at each step of this flow by using the Network Panel that you can access through your browser's Developer Tools. First, visit quotes.toscrape.com/search.aspx and then load the tool by pressing F12 or Ctrl+Shift+I (if you are using Chrome) and clicking on the Network tab.

Select an author from the list and you will see that a request to "/filter.aspx" has been made. Clicking on the resource name (filter.aspx) leads you to the request details where you can see that your browser sent the author you've selected along with the __VIEWSTATE data that was in the original response from the server.
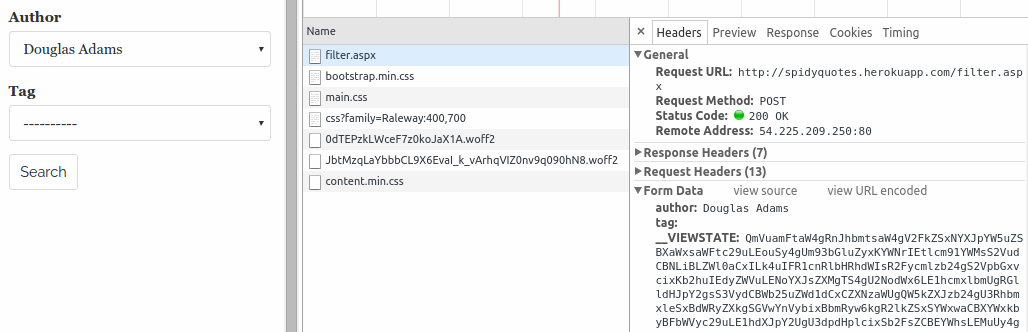
Choose a tag and click Search. You will see that your browser sent the values selected in the form along with a __VIEWSTATE value different from the previous one. This is because the server included some new information in the view state when you selected the author.
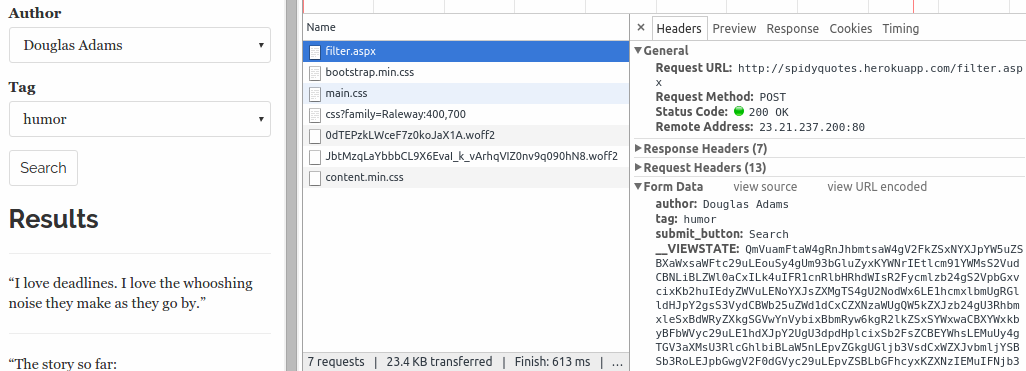
Now you just need to build a spider that does the exact same thing that your browser did.
Building your Spider
Here are the steps that your spider should follow:
- Fetch quotes.toscrape.com/search.aspx
- For each Author found in the form's authors list:
- Create a POST request to /filter.aspx passing the selected Author and the __VIEWSTATE value
- For each Tag found in the resulting page:
- Issue a POST request to /filter.aspx passing the selected Author, selected Tag and view state
- Scrape the resulting pages
Coding the Spider
Here's the spider I developed to scrape the quotes from the website, following the steps just described:
import scrapy class SpidyQuotesViewStateSpider(scrapy.Spider): name = 'spidyquotes-viewstate' start_urls = ['http://quotes.toscrape.com/search.aspx'] download_delay = 1.5 def parse(self, response): for author in response.css('select#author > option ::attr(value)').extract(): yield scrapy.FormRequest( 'http://quotes.toscrape.com/filter.aspx', formdata={ 'author': author, '__VIEWSTATE': response.css('input#__VIEWSTATE::attr(value)').extract_first() }, callback=self.parse_tags ) def parse_tags(self, response): for tag in response.css('select#tag > option ::attr(value)').extract(): yield scrapy.FormRequest( 'http://quotes.toscrape.com/filter.aspx', formdata={ 'author': response.css( 'select#author > option[selected] ::attr(value)' ).extract_first(), 'tag': tag, '__VIEWSTATE': response.css('input#__VIEWSTATE::attr(value)').extract_first() }, callback=self.parse_results, ) def parse_results(self, response): for quote in response.css("div.quote"): yield { 'quote': quote.css('span.content ::text').extract_first(), 'author': quote.css('span.author ::text').extract_first(), 'tag': quote.css('span.tag ::text').extract_first(), }
Step 1 is done by Scrapy, which reads start_urls and generates a GET request to /search.aspx.
The parse() method is in charge of Step 2. It iterates over the Authors found in the first select box and creates a FormRequest to /filter.aspx for each Author, simulating if the user had clicked over every element on the list. It is important to note that the parse() method is reading the __VIEWSTATE field from the form that it receives and passing it back to the server, so that the server can keep track of where we are in the page flow.
Step 3 is handled by the parse_tags() method. It's pretty similar to the parse() method as it extracts the Tags listed and creates POST requests passing each Tag, the Author selected in the previous step and the __VIEWSTATE received from the server.
Finally, in Step 4 the parse_results() method parses the list of quotes presented by the page and generates items from them.
Simplifying your Spider Using FormRequest.from_response()
You may have noticed that before sending a POST request to the server, our spider extracts the pre-filled values that came in the form it received from the server and includes these values in the request it's going to create.
We don't need to manually code this since Scrapy provides the FormRequest.from_response() method. This method reads the response object and creates a FormRequest that automatically includes all the pre-filled values from the form, along with the hidden ones. This is how our spider's parse_tags() method looks:
def parse_tags(self, response): for tag in response.css('select#tag > option ::attr(value)').extract(): yield scrapy.FormRequest.from_response( response, formdata={'tag': tag}, callback=self.parse_results, )
So, whenever you are dealing with forms containing some hidden fields and pre-filled values, use the from_response method because your code will look much cleaner.
Wrap Up
And that’s it for this month! You can read more about ViewStates here. We hope you found this tip helpful and we’re excited to see what you can do with it. We’re always on the lookout for new hacks to cover, so if you have any obstacles that you’ve faced while scraping the web, please let us know.
Feel free to reach out on Twitter or Facebook with what you’d like to see in the future.