Splash 2.0 is here with Qt 5 and Python 3
We’re pleased to announce that Splash 2.0 is officially live after many months of hard work.
For those unfamiliar with Splash, it’s a headless browser we developed specifically for web crawling. Splash executes and renders JavaScript so you can deal with dynamic content. It also supports scripting so you can perform actions on the page.
Splash is open source and fully integrated with Scrapy and Portia. You can also use its API to integrate with any project that needs to render JavaScript pages. Splash is included with Scrapy Cloud and is supported without any additional dependencies. You can also run a Splash instance on your own infrastructure, so there is no platform lock-in.
Splash 2.0 now runs on Qt 5 and brings Python 3 support, lots of UI improvements and many other changes and bug fixes.
Improvements
Python 3 support and Qt 5
We’ve added support for Python 3 and the Docker container now uses it by default instead of Python 2.
Splash now runs on Qt 5 which brings improved JavaScript and HTML5 features such as CSS filters and canvas.
We would like to thank Tarashish Mishra, who joined us through Google Summer of Code 2015, for all his hard work in doing the initial port for Qt 5 and Python 3. If you want to contribute in some of our projects, please stay tuned for GSoC 2016.
Built-in support for JSON and Base64
We’ve also included modules for JSON and Base64 so you no longer need to include foreign libraries.
Script examples
You can now find script examples in a new drop-down menu named ‘Examples’:
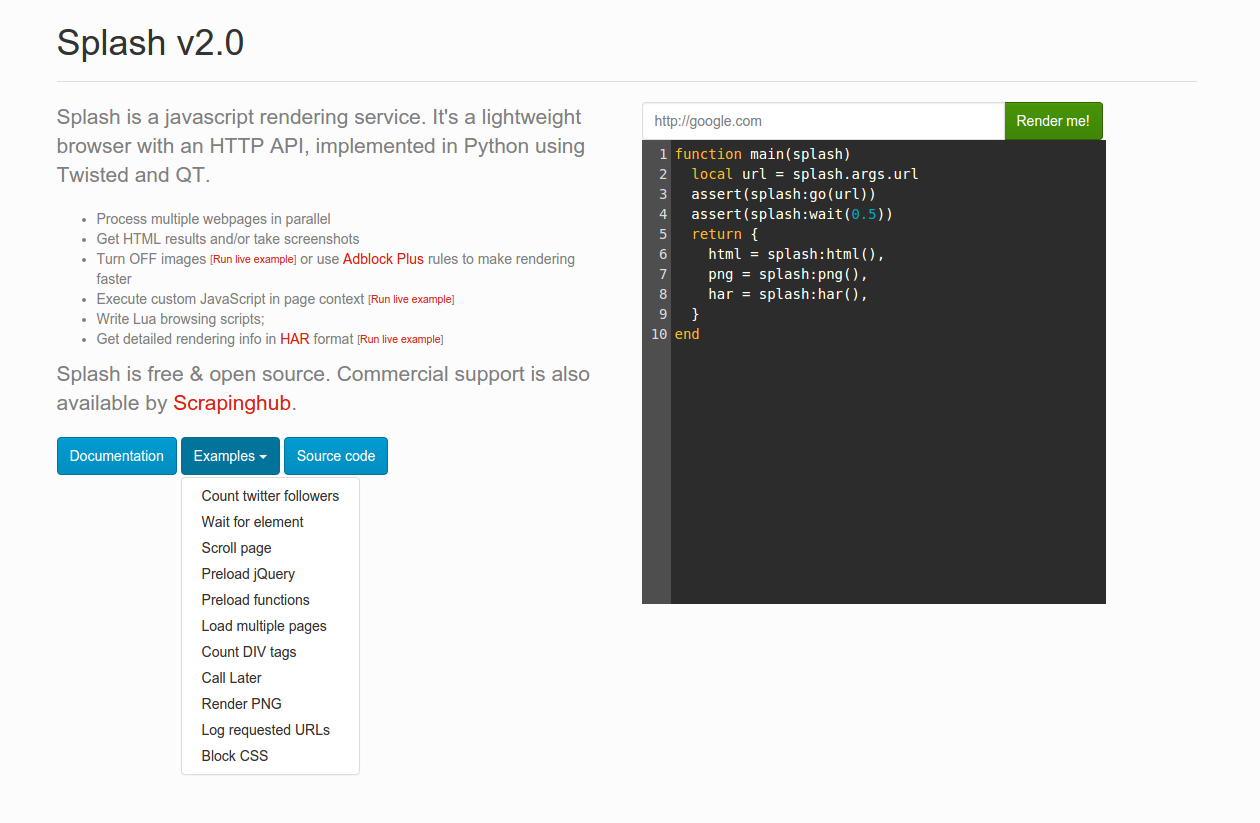
Friendlier UI
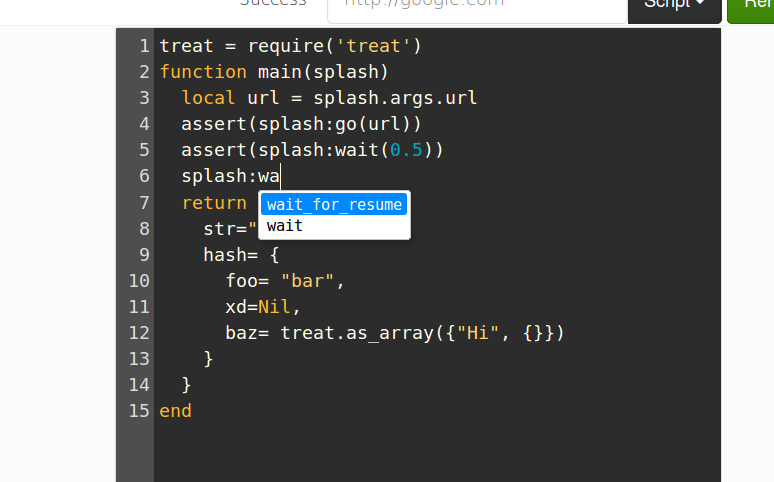
Auto-completion of Splash methods:
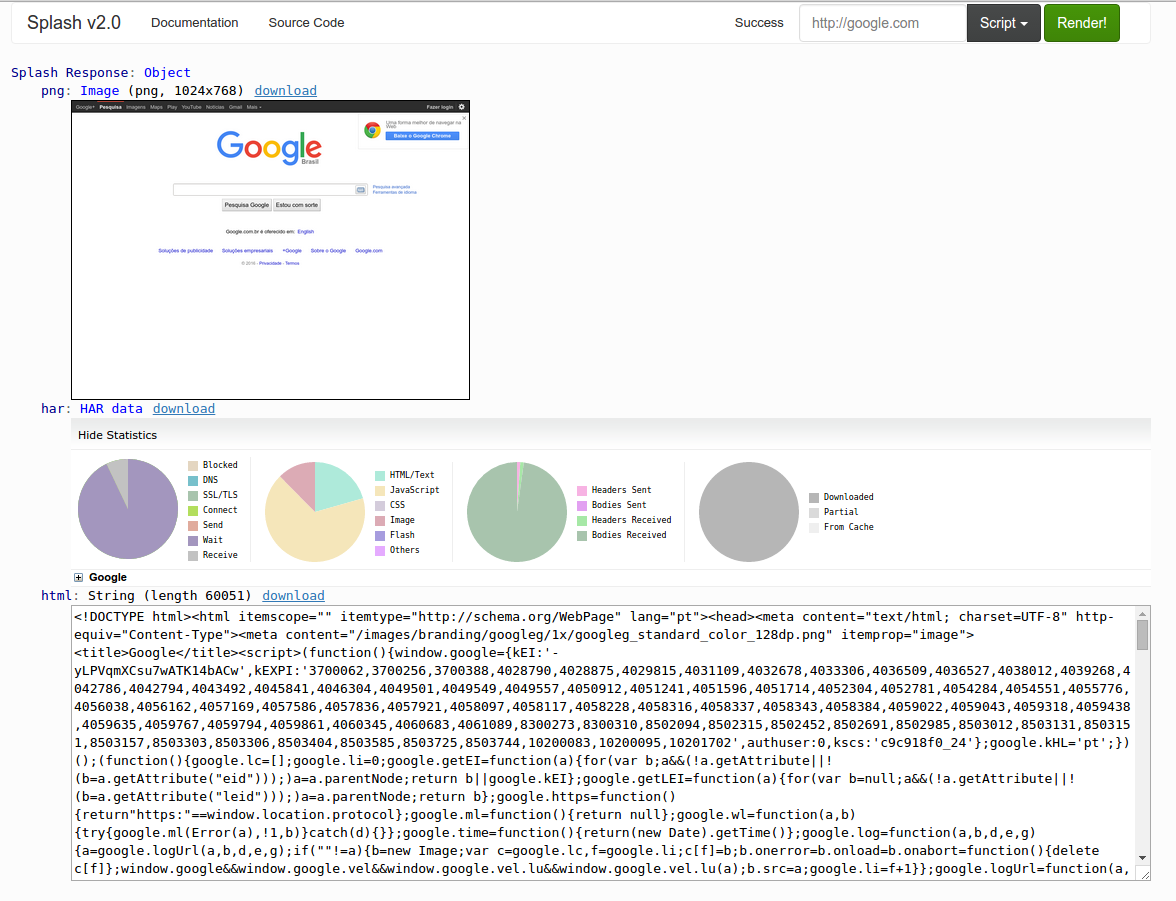
Default script result:
Bug Fixes
Cookies
We fixed a bug which prevented cookies being set via JavaScript as well as one which resulted in cookies being shared across tabs.
Proxy authentication
We fixed a bug that prevented users from updating proxy settings after request:set_proxy had been called.
Backwards-incompatible changes
We also made the following backwards-incompatible changes:
QT-based disk cache
Splash no longer supports the QT-based disk cache. We have discouraged usage since 1.0 and we recommend using something more reliable like Squid.
Serialization of JavaScript objects
We’ve made changes to how splash:jsfunc, splash:evaljs and splash:wait_for_resume serialize objects. Circular objects are no longer returned and DOM elements are no longer serialized.
Splash-as-a-proxy
We removed the Splash-as-a-proxy service because it didn’t work with HTTPS and we wanted to reduce the dependency on advanced Twisted features. There was also an issue with the X-Splash-js-source header due to Python treating headers with values containing new lines as unsafe.
Splash scripting
We made a few backwards-incompatible changes to Splash scripting as well and there’s a small chance you will need to update your scripts. Here are the changes we’ve made:
Receiving a response object. You should now use the returned object’s info attribute.
resp = splash:http_get(...) should be replaced with resp = splash:http_get(...).info
resp = splash:http_post(...) should be replaced with resp = splash:http_post(...).info
You should also do the same for the response object received by splash:on_response_headers and splash:on_response.
Default encoding of info['content']['text'] is now Base64.
You can find the full release notes here.
Wrap Up
Thanks for reading and hope you enjoy using Splash! Take a look at our previous blog post to learn more about using Splash in your Scrapy projects. Also stay tuned because we have an even bigger release coming soon. You won’t want to miss it.