Portia: The open-source alternative to Kimono labs
Note: Portia is no longer available for new users. It has been disabled for all the new organisations from August 20, 2018 onward.
Attention Kimono users: we've created an exporter so you can easily convert your projects from Kimono to Portia!
Imagine your business depended heavily on a third party tool and one day that company decided to shut down its service with only 2 weeks notice. That, unfortunately, is what happened to users of Kimono Labs yesterday.
And it’s one of the many reasons why we love open source so much.
Portia is an open source visual scraping tool developed by Zyte to make it easier to get data from the web without needing to write a line of code.
You can do anything with Portia that you can with Kimono Labs, but without vendor lock-in. This allows you to run your spiders on our platform, but you always have the option to move to your own infrastructure.
Also, we won’t be leaving you high and dry, Kimono users. We've developed an exporter to easily migrate your Kimono projects to Portia. Check it out: kimono.Zyte.com
Portia’s Features
- Open source (you won’t need to worry about us shutting down on you)
- You can always export all your data and your crawler configurations
- Support for JavaScript-based websites
- User interactions (such as click, scroll, wait, filling forms) are simulated by recording and replaying user actions on the page
- Browser-based, so there’s no need for extensions
- Portia is based on Scrapy, and can be extended and customized further using code
Get started with Portia here. And take a look at our Knowledge Base in case you have any questions.
Kimono and Portia
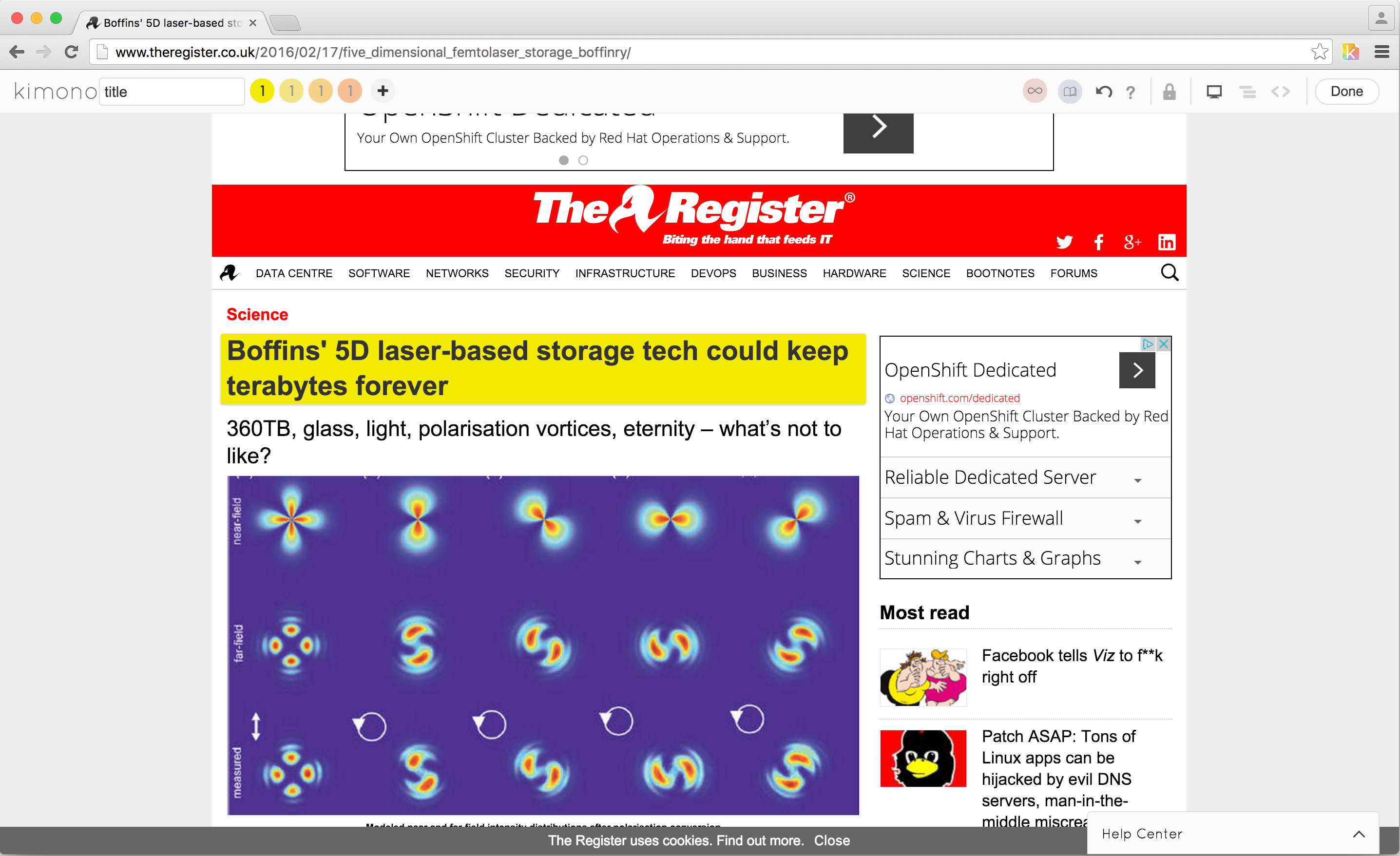
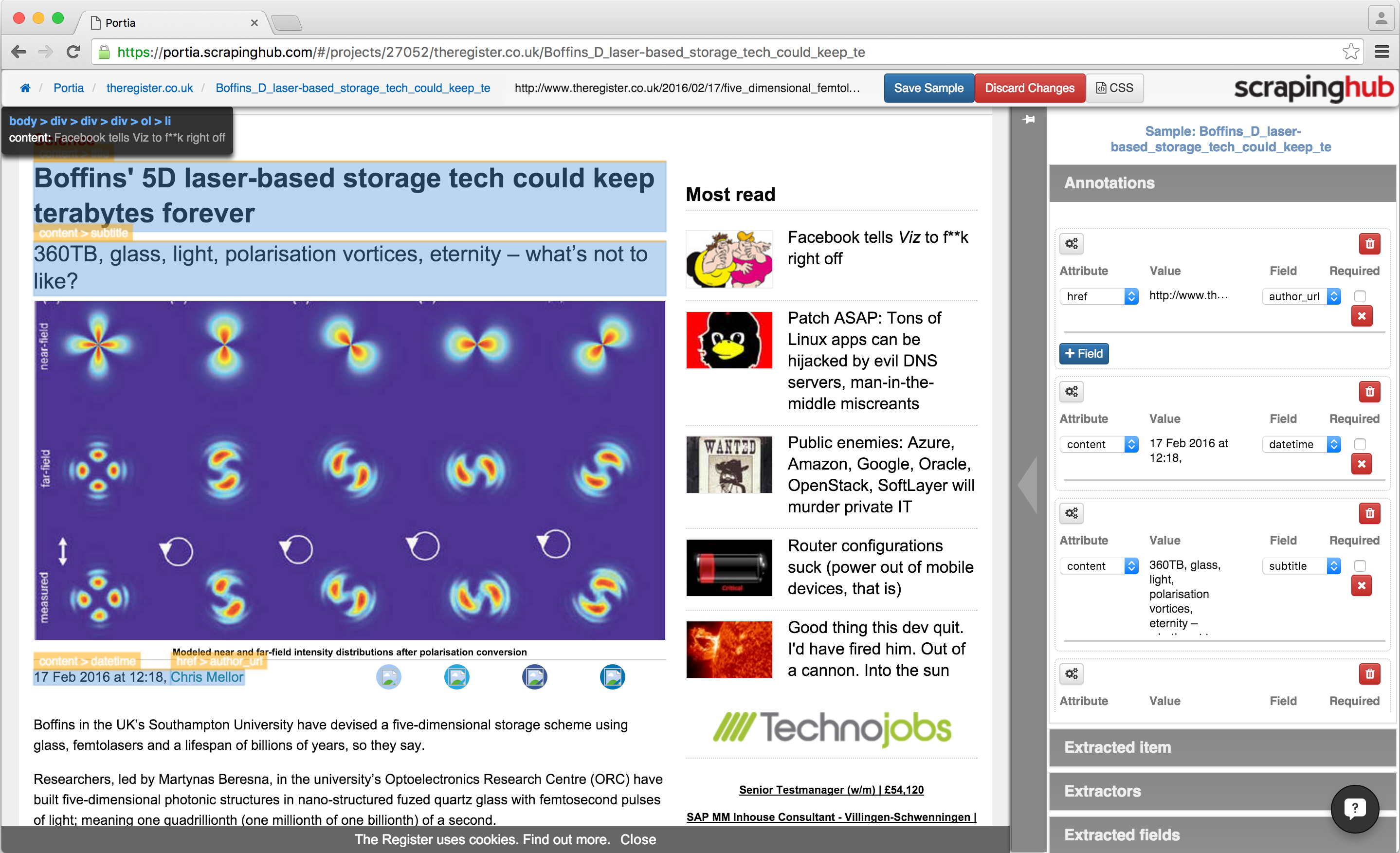
Take a look at Kimono and Portia in action:
Portia 2.0
Our upcoming Portia 2.0 release includes:
- Extracting multiple items from a list
- Nested items support
- New, revamped UI based on user experiences
And soon after, we’ll also be adding new features like:
- A visual method of defining links to follow without the need for regular expressions.
- A way to download Portia projects as Scrapy projects using CSS and XPath selectors
Scalable Platform
Portia is fully integrated into our platform, Scrapy Cloud, but you can also checkout the repository and run it locally or on your own server. The benefits of running Portia on Scrapy Cloud include:
- Robust scheduling
- On-demand scaling
- Monitoring add-on that checks if all the expected items were extracted for each crawl
- View and compare the items extracted through its UI
- Built-in add-ons for Crawlera and Splash, along with third party tools
Wrap Up
Since Portia is open source, we welcome any and all developers who are interested in contributing.
