Aduana: Link analysis to crawl the web at scale
Crawling vast numbers of websites for specific types of information is impractical. Unless, that is, you prioritize what you crawl. Aduana is an experimental tool that we developed to help you do that. It’s a special backend for Frontera, our tool to expedite massive crawls in parallel (primer here).
Aduana is designed for situations where the information you’re after is dispersed all over the web. It provides you with two link analysis algorithms, PageRank and HITS (how they work). These algorithms analyze link structure and page content to identify relevant pages. Aduana then prioritize the pages you’ll crawl next based on this information.

You can use Aduana for a number of things. For instance:
- Analyzing news.
- Searching locations and people.
- Performing sentiment analysis.
- Finding companies to classify them.
- Extracting job listings.
- Finding all sellers of certain products.
Concrete example: imagine that you’re working for a travel agency and want to monitor trends on location popularity. Marketing needs this to decide what locations they’ll put forward. One way you could do this is by finding mentions of locations on news websites, forums, and so forth. You’d then be able to observe which locations are trending and which ones are not. You could refine this even further by digging into demographics or the time of year - but let’s keep things simple for now.
This post will walk you through that scenario. We’ll explore how you can extract locations from web pages using geotagging algorithms, and feed this data into Aduana to prioritize crawling the most relevant web pages. We’ll then discusses how performance bottlenecks led us to build Aduana in the first place. We'll lastly give you its backstory and a glimpse at what’s coming next.
In case you’d like to try this yourself as you read, you’ll find the source code for everything discussed in this post in the Aduana repository’s examples directory.
Using GeoNames and Neural Networks to Guide Aduana
Geotagging is a hard problem
Extracting location names from arbitrary text is a lot easier said than done. You can’t just take a geographical dictionary (a gazetteer) and match its contents against your text. Two main reasons:
- Location names can look like common words.
- Multiple locations can share the same name.
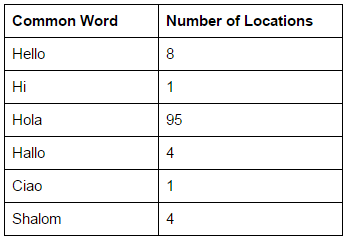
For instance, GeoNames references 8 locations called Hello, one called Hi, and a whopping 95 places called Hola:
Using Named-Entity Recognition to Extract Location Names
Our first idea was to use named-entity recognition (NER) to reduce the number of false positives and false negatives. A NER tokenizer allows to classify elements in a text into predefined categories such as person names or location names. We figured we’d run our text through the NER and match the relevant output against the gazetteer.
CLAVIN is one of the few open source libraries available for this task. It uses heuristics that disambiguate locations based on the text’s context.
We built a similar solution in Python. It’s based on NLTK, a library for natural language processing that includes a part of speech (POS) tagger. A POS tagger is an algorithm that assigns parts of speech - e.g. noun or verb - to each word. This lets us extract geopolitical entities (GPEs) from a text directly. And then match the GPEs against GeoNames to get candidate locations.
The result is better than naive location name matching but not bulletproof. Consider the following paragraph from this blog entry to illustrate:
Bilbao can easily be seen in a weekend, and if you’re really ambitious, squeezed into 24 hours. Lots of tourists drop in before heading out to San Sebastián, but a quick trip to the Bizkaia province leaves out so many beautiful places. Puerto Viejo in Algorta – up the river from Bilbao on the coast – is one of those places that gets overlooked, leaving it for only for those who’ve done their research.
Green words are locations our NER tokenizer recognized. Red words are those it missed. As you can see, it ignored Bizkaia. It also missed Viejo after incorrectly splitting Puerto Viejo in two separate words.
Undeterred, we tried a different approach. Rather than extracting GPEs using a NER and feeding them directly into a gazetteer, we’d use the gazetteer to build a neural network and feed the GPEs into that instead.
Using a Hopfield Network to Extract Location Names
We initially experimented with centrality measures using the NetworkX library. In short, a centrality measure assigns a score to each node in a graph to represent its importance. A typical one would be PageRank.
But we were getting poor results: nodes values were too similar. We were leaning towards introducing non-linearities to the centrality measures to work around that. When it hit us: a special form of recurrent neural network called a Hopfield network had them built-in.
We built our Hopfield network (source code) with each unit representing a location. Unit activation values range between -1 and +1, and represent how sure we are that a location appears in a text. The network’s links connect related locations with positive weights - e.g. a city with its state, a country with its continent, or a country with neighboring countries. Links also connect mutually exclusive locations with negative weights, to address cases where different locations have identical names. This network then lets us pair each location in a text with the unit that has the highest activation.
You’d normally train such a network’s weights until you minimize an error function. But manually building a training corpus would take too much time and effort for this post’s purpose. As a shortcut, we simply set the weights of the network with fixed values (an arbitrary +1 connection strength for related locations) or using values based on GeoNames (an activation bias based on the location’s population relative to its country).
The example we used earlier yields the following neural network:

Colors represent the final unit activations. Warmer colors (red) show activated units; cooler colors (blue) deactivated ones.
The activation values for our example paragraph are:
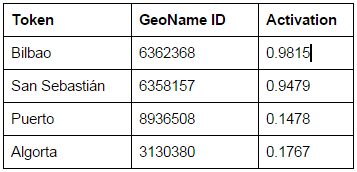
The results are still not perfect but very promising. Puerto gets recognized as Puerto Viejo but is incorrectly assigned to a location in Mexico. This may look strange at first, but Mexico actually has locations named San Sebastián and Bilbao. Algorta is correctly identified but received a low score. It’s too weakly connected to the related locations in the graph. Both issues occur because we didn’t train our network.
That’s sensible and good enough for our purpose. So let’s move forward and make Aduana use this data.
Running the Spider
You can safely skip this section if you’re not running the code as you read.
You’ll find the spider’s source code in the Aduana repository and Aduana installation instructions in the documentation.
To run the spider:
git clone https://github.com/scrapinghub/aduana.git cd aduana python setup.py develop cd examples/locations pip install -r requirements.txt scrapy crawl locations
If you get problems with the dependencies - namely with numpy and scipy - install them manually. One at a time, in order:
pip install numpy pip install scipy pip install sklearn
Prioritizing Crawls Using Aduana
Our spider starts with a seed of around 1000 news articles. It extracts links to new pages and location data as it crawls. It then relies on Aduana to tell it what to crawl next.
Each page’s text goes through our geotagging algorithm. Our spider only keeps locations with an activation score of 0.90 or above. It outputs the rows in a locations.csv file. Each row contains the date and time of the crawl, the GeoName ID, the location’s name, and the number of times the location appears in the page.
Our spider uses this data to compute a score for each page. The score is a function of the proportion of locations in the text:

Aduana then uses these scores as inputs for its HITS algorithm. This allows it to identify which pages are most likely to mention locations and rank pages on the fly.
Promising Results
Our spider is still running as we write this. Aduana ranked about 2.87M web pages. Our spider crawled 129k. And our geotagging algorithm found over 300k locations on these pages. The results so far look good.
In a future blog post we’ll dig into our findings and see if anything interesting stands out.
To conclude this section, Aduana helps a lot to guide your crawler when running broad crawls. And depending on what you’re using it for, consider implementing some kind of machine learning algorithm to extract the information you need to compute page scores.
Aduana Under the Hood
Performance problems with graph databases
If you’re familiar with graph databases, you may have been wondering all along why we created Aduana instead of using off-the-shelf solutions like GraphX and Neo4j. The main reason is performance.
We actually wanted to use a graph database at first. We figured we’d pick one, write a thin layer of code so Frontera can use it as a storage backend, and call it a day. This was the logical choice because the web is a graph and popular graph databases include link analysis algorithms out of the box.
We chose GraphX because it’s open source and works with HDFS. We ran the provided PageRank application on the LiveJournal dataseed. The results were surprisingly poor. We cancelled the job 90 minutes in. It was already consuming 10GB of RAM.
Wondering why, we ended up reading GraphChi: Large-Scale Graph Computation on Just a PC. It turns out that running PageRank on a 40 million node graph is only twice as fast as running GraphChi on a single computer. That eye opener made us reconsider whether we should distribute the work.
We tested a few non-distributed libraries with same LiveJournal data. The results:
- FlashGraph: 12 seconds
- X-Stream: 20 seconds
- SNAP: 6 minutes
To be clear, take these timings with a grain of salt. We only tested each library for a brief period of time and we didn’t fine-tune anything. What counted for us was the order of magnitude. The non-distributed algorithms were much faster than the distributed ones.
We then came across two more articles that confirmed what we had found: Scalability! But at what COST? and Bigger data; same laptop. The second one is particularly interesting. It discusses computing PageRank on a 128 billion edge graph using a single computer.
In the end, SNAP wasn’t fast enough for our needs, and FlashGraph and X-Stream were rather complex. We realized it would be simpler to develop our own solution.
Aduana Is Built on Top of LMDB
With this in mind, we began implementing a Frontera storage engine on top of a regular key-value store: LMDB. Aduana was born.
We considered using LevelDB. It might have been faster. LMDB is optimized for reads after all; we do a lot of writing. We picked LMDB regardless because:
- It’s easy to deploy: only 3 source files written in C.
- It’s plenty fast.
- Multiple processes can access the database simultaneously.
- It released under the OpenLDAP license: open source and non-GPL.
When Aduana needs to recompute PageRank/HITS scores, it stores the vertex data as a flat array in memory, and streams the links between them from the database.
Using LMDB and writing the algorithms in C was well worth the effort in the end. Aduana now fits a 128 billion edge graph onto a 1TB disk, and its vertex data in 16GB of memory. Which is pretty good.
Let’s now segue into why we needed any of this to begin with.
Aduana’s Backstory and Future
Aduana came about when we looked into identifying and monitoring specialized news and alerts on a massive scale for one of our Professional Services clients.
To cut a long story short, we wanted to locate relevant pages first rather than on an ad hoc basis. We also wanted to revisit the more interesting ones more often than the others. We ultimately ran a pilot to see what happens.
We figured our sheer capacity might be enough. After all, our cloud-based platform’s users scrape over two billion web pages per month. And Crawlera, our smart proxy rotator, lets them work around crawler countermeasures when needed.
But no. The sorry reality is that relevant pages and updates were still coming in too slowly. We needed to prioritize more. That got us into link analysis and ultimately to Aduana itself.
We think Aduana is a very promising tool to expedite broad crawls at scale. Using it, you can prioritize crawling pages with the specific type of information you’re after.
It’s still experimental. And not production-ready yet. Our next steps will be to improve how Aduana decides to revisit web pages. And make it play well with Distributed Frontera.
If you’d like to dig deeper or contribute, don’t hesitate to fork Aduana’s Github repository. The documentation includes a section on Aduana's internals if you’d like to extend it.
As an aside, we’re hiring; and we're for hire if you need help turning web content into useful data.