Distributed Frontera: Web crawling at scale
Welcome to distributed Frontera: Web crawling at scale
This past year, we have been working on a distributed version of our crawl frontier framework, Frontera. This work was partially funded by DARPA and is included in the DARPA Open Catalog.
The project came about when a client of ours expressed interest in building a crawler that could identify frequently changing hubs.
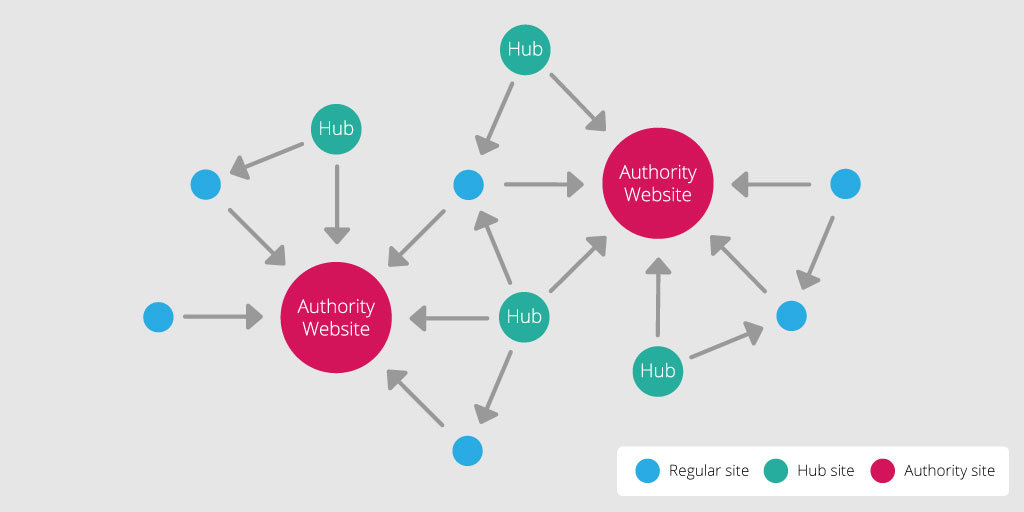
Hubs are web pages that contain a large number of outgoing links to authority sites. For example, Reddit, the DMOZ Directory, and Hacker News are hubs because they point to a lot of pages with authoritative content. Authorities are sites that obtain a high authority score, determined by the relevant information on the page and its authoritative sources. Examples of authorities include the Huffington Post and Lifehacker.
And so for this project, we needed to be able to crawl around 1 billion pages per week, batch process them and then output the frequently changing hubs. And that's what you can call web crawling at scale. Furthermore, these were characterized as pages that significantly change their outgoing links.
Single-thread mode
We began by building a single-thread crawl frontier framework. This allowed us to store and generate batches of documents to crawl with a framework that works seamlessly with the Scrapy ecosystem.
This is basically the original Frontera, which solves:
- Cases when you need to isolate URL ordering/queueing from the spider e.g. distributed infrastructure, remote management of ordering/queueing.
- Cases when URL metadata storage is needed e.g. to show storage contents.
- Cases when you need advanced URL ordering logic: If a website is large, it can be expensive to crawl the whole thing, so Frontera is used for crawling the most important documents.
Single-thread Frontera has two storage backends: memory and SQLAlchemy. You can use any RDBMS of your choices such as SQLite, MySQL, and Postgres. If you wish to use your own crawling strategy, you will need to create a custom Frontera backend and use it in the spider.
You can find the repository here.
Distributed mode
We began investigating how to scale this existing solution and make it work with an arbitrary number of documents. Considering our access pattern, we were interested in scalable key-value storage that could offer random read/writes and efficient batch processing capabilities.
HBase turned out to be a good choice for this. Mail.ru, for example, is a web search engine with a content system built on top of HBase.
However, direct communication between HBase and Python wasn’t reliable so we decided to use Kafka as a communication layer.
Kafka Overview
For those who are unfamiliar, Kafka is a distributed messaging system. The way that Kafka operates is that it manages a data stream of messages, known as topics, that are segmented into partitions.
In a Kafka setup, there are producers and consumers. Producers create and publish messages on the topic. Consumers subscribe to and process the messages in the topic. The consumer offset refers to the position of the consumer in a topic as it processes the messages.
Our Kafka Setup
Storing the spider log in Kafka allowed us to replay the log out of the box, which can be useful when changing the crawling strategy on the fly. We were able to set up partitions by domain name, which made it easier to ensure that each domain was downloaded at most by one spider.
We used the consumer offset feature to track the position of the spider and provide new messages slightly ahead of time in order to prevent topic overload by deciding if the spider was ready to consume more.
Architecture
Here is a diagram of our complete Distributed Frontera architecture:
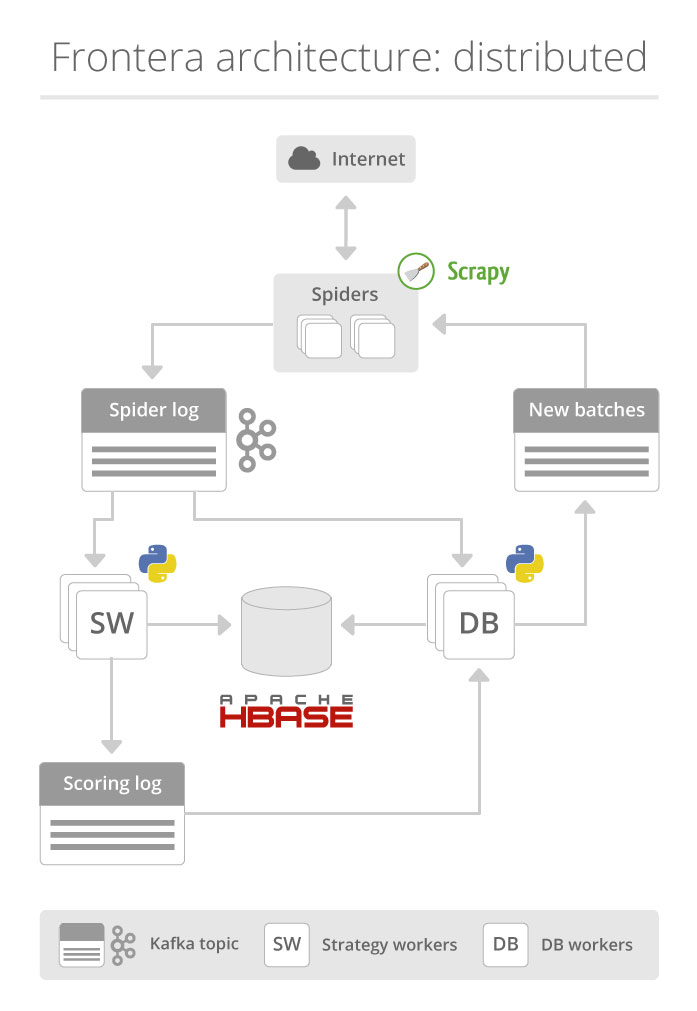
Let’s start with the spiders. The seed URLs are propagated to strategy workers and DataBase (DB) workers by means of a Kafka topic named 'Spider Log'. Strategy workers decide which pages to crawl using the document states stored in HBase. The workers then assign a score to each page and send the results to the 'Scoring Log' topic.
A DB worker stores all kinds of metadata, including content and scores. The DB worker checks the consumer offset of the spiders, generating new batches if needed and sending them to the ‘New Batches’ topic. Spiders consume these batches, downloading each page and extracting links from them. The links are then sent to the ‘Spider Log’ topic where they are stored and scored. And that's it, we have a closed circle.
Advantages
The main advantage of this design is real-time operation. The crawling strategy can be changed without having to stop the crawl. It’s worth mentioning that the crawling strategy can be implemented as a separate module. This module would contain the logic for ordering URLs and stopping crawls, as well as the scoring model.
Distributed Frontera is polite to web hosts by design because each host is downloaded by only one spider process. This is achieved by Kafka topic partitioning. All distributed Frontera components are written in Python. Python is much simpler to write than C++ or Java, the two most common languages for large-scale web crawlers.
Here are some of the possible uses for Distributed Frontera:
- You have a set of URLs and need to revisit them e.g. to track changes.
- You are building a search engine with content retrieval from the Web.
- All kinds of research work on web graphs: gathering link statistics, analyzing the graph structure, tracking domain count, etc.
- You have a topic and you want to crawl the pages related to that topic.
- More general focused crawling tasks e.g. searching for pages that are large hubs and which change frequently.
Hardware requirements
One spider thread can crawl around 1200 pages/minute from 100 web hosts in parallel. The spider to worker ratio is about 4:1 without content; storing content could require more workers.
1 GB of memory is required for each strategy worker instance in order to run the state cache. The size of the state cache can be accommodated through a settings adjustment. For example, if you need to crawl 15K pages/minute, you would need 12 spiders and 3 pairs of strategy workers and DB workers. All these processes would consume 18 cores in total.
Using distributed Frontera
You can find the repository here.
This tutorial should help you get started and there are also some useful notes in the slides that I presented at EuroPython 2015.
You may also want to check out the Frontera documentation as well as our previous blog post that provides an example of using Frontera in a single process mode.
Thanks for reading! If you have any questions or comments, please share your thoughts below.
References
- Resources for hubs and authorities
- Resources on link analysis algorithms
- HBase was modeled after Google's BigTable system
- Mail.ru web crawler article (Russian)
- A strategy worker can be implemented using a different language, the only requirement is a Kafka client.