Finding similar items
Near duplicate content is everywhere on the web and needs to be considered in any web crawling project.
Web pages might differ only in a small portion of their content, such as advertising, timestamps, counters, etc. This fact can be used when crawling to improve quality and performance and there are efficient ways to detect these near-duplicate web pages[1].
However, there are times when you need to identify similar items in the extracted data. This could be unwanted duplication, or we may want to find the same product, artist, business, holiday package, book, etc. from different sources.
As an example, let’s say we’re interested in compiling information on tourist attractions in Ireland and would like to output each attraction, with links to various websites where more information can be found. Consider the following examples of records that could be crawled:
| Name | Summary | Location |
|---|---|---|
| Saint Fin Barre's Cathedral | Begun in 1863, the cathedral was the first major work of the Victorian architect William Burges... | 51.8944, -8.48064 |
| St. Finbarr’s Cathedral Cork | Designed by William Burges and consecrated in 1870, .. | 51.894401550293, -8.48064041137695 |
Although they are obviously the same place, there’s not much textual similarity between these two records. “Cathedral” is the only word in common in the name, and we have a lot of those in Ireland!
It turns out there are other common spellings of St. Fin Barre's, many websites list it multiple times (not realizing they have duplicates) and not all websites have the location listed.
Finding Similar Text
A common way to implement this is to first produce a set of tokens (could be hashes, words, shingles, sketches, etc.) from each item, measure the similarity between each pair of sets and if it’s above a threshold then the items are said to be near duplicates.
Consider the name fields in the example above. If we split each into words, then we can say that they have one word in common out of a total of 7 unique words - a similarity of 14% [2].
Unfortunately, comparing all pairs of items is only feasible when we have very few items[3]. It may work (eventually) for tourist attractions in Ireland, but we need to use this on hundreds of millions of items. Instead of comparing all pairs, we restrict it to only pairs with at least one token in common (e.g. by using an inverted index). The performance of this approach depends mainly on how many “candidate pairs” are generated.
The quality of the similarity function can be improved by generating better tokens. Firstly, we could make a database of common synonyms, and recognize that “St.” is an abbreviation for “Saint” (and street - be careful!). Now we have 2 in common out of 6 unique words - up to 33%! In addition to synonyms, it’s a good idea to remove markup, ignore case, include stop words (reduces false-positives and the number of candidate pairs), and stem words. There are other possible ways to generate tokens instead of using words, such as by taking into account position, adjacent words, using the characters that make up the words, extracting “entities”, etc.
For a more detailed description, please see the excellent book Introduction to Information Retrieval. Tokenization and linguistic processing are covered in Section 2.2 and section 19.6 covers near-duplicate detection.
Extending Similarity to Items
Including more fields in the similarity calculation will make it more accurate. Returning to our example, there are many cathedrals named after saints, but the location can narrow it down. Additionally, the description can help disambiguate from other crawled items (e.g. hotels near St. Fin Barre’s Cathedral).
The same techniques as described above can be used to make tokens for the description. We just have to be aware that longer text generates more candidate matches and is more likely to be similar to other random text, so taking multiple words together as the tokens is a good idea. For example, instead of:
begun, in, 1863, the, cathedral,...
We take each 3 adjacent words:
begun in 1863, in 1863 the, 1863 the cathedral, ...
This technique is called Shingling and is commonly used when calculating similarity.
The location needs to be treated differently. The two examples given above happen to share many digits, but that won’t always be the case. We use geohash to convert the coordinates into a bucket and use both the bucket and its neighbors as the tokens. For our first example record, we generate the following buckets:
Locations that are close will share some buckets.
Counting tokens in common across multiple fields gives poor results; the field with the most tokens (description in our example) will completely dominate the calculation. Instead, we calculate the similarity between each field in common (name, description, location) individually and combine these similarities into a total similarity for the pair of items. When combining scores, we can give more weight to more important fields.
Super Tokens[4]
With a high enough similarity threshold, we can prove that some similarity in multiple fields is necessary for the final score to be above the threshold. Therefore, we can generate tokens that combine the token data of more than one field into “super tokens”. Although there are more tokens generated, they will be much rarer and this reduces the size of the candidate pairs and improves performance significantly.
We observed that requiring a match on multiple fields can improve the quality and we can use super tokens to encode these rules. In our example, we could add a rule saying that we must match on either (name, description) or (name, location) and generate super tokens for these field combinations. For (name, description) with shingling of description, the first example record would have the following tokens:
st. begun in 1863, st. in 1863 the, st. 1863 the cathedral, ... fin begun in 1863, fin in 1863 the, fin 1863 the cathedral, ... barre begun in 1863, barre in 1863 the, barre 1863 the cathedral, ... ...
Producing the Same Item
Once we have found pairs of similar items, the next step is to merge these into a single item. In our case, we want to find all St. Fin Barre's Cathedrals in our data and output a single record with links.
The first thing to notice is that similarity is not transitive - if A is similar to B and B is similar to C, our function may not find A similar to C. So, we connect these into clusters and generate our output from the connected-up items.
In practice, these clusters can sometimes get too large as a weak similarity between clusters can cause them to be merged, resulting in large clusters of unrelated items. We found that algorithms designed for detecting communities in social networks are able to efficiently generate good clusters. The following example is from a large crawl, where a single item has some similarity with many different items, causing their respective clusters to get connected:
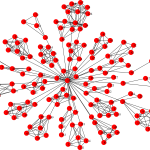 A large cluster containing different items A large cluster containing different items |
| 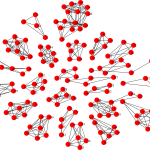 The cluster is split into many smaller clusters The cluster is split into many smaller clusters |
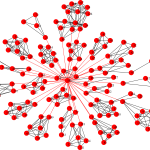 Unwanted links are identified
Unwanted links are identifiedIt's like someone who friends everyone on Facebook!
The final step is to output a record for each cluster. In our example, we would output the attraction name, and a link to each page we found it on.
Summary
We have described a system for finding similar items in scraped data. We have implemented it as a library based on MapReduce, which has been in use for over a year and has proven successful on many scraping projects.
If you are interested in using this on your crawling project, please contact our Professional Services team.
- We implemented a version of Charikhar's Simhash, as described in the WWW 2007 paper, "Detecting Near-Duplicates for Web Crawling" (PDF) by Gurmeet Manku, Arvind Jain, and Anish Sarma. The performance of this algorithm is excellent.
- This method of calculating similarity is called the Jaccard Index.
- The running time proportional to the square of the number of items. If we have 10x the number of items, it takes 100 times longer to process.
- Super Tokens are tokens of tokens. This is analogous to the Super Shingles proposed by Broder et al.